网络爬虫框架Scrapy的使用
发布者:
Jeremy Peng
1 简介
有时候我们需要从各种网页或网站中,获取我们需要的信息或者内容,通常我们可以通过urllib 获取网页的html 代码,然后利用BeautifulSoup 或lxml 等xml parser解析出我们需要的内容。
但是这种解析方法和过程比较繁琐,代码最后也会有很多的各种html tag判断分支,构成的爬虫程序通常比较复杂,难以维护和复用。
这时候我们需要一个简单易用的“爬虫框架” 来为我们完成繁琐的数据获取过程,使得我们能更专注于数据处理上。
Scrapy comes to help!
Scrapy 是基于python 一个开源的“网络爬虫” 框架,功能上要比基于 BeautifulSoup 或 lxml 的爬虫强大, 用官方的一句话:
In other words, comparing BeautifulSoup (or lxml) to Scrapy is like comparing jinja2 to Django.
Scrapy 现在暂时只支持Python2.7版本(3.0 不支持), 2.6版本的python 只能使用scrapy 0.20.
2 安装
scrapy的安装极其简单,只需要执行:
pip install scrapy经过漫长的等待, scrapy终于安装完成。(如果之前没有安装过pip, 请移步)
然后再终端里执行“scrapy”,即能看到scrapy相关信息,要是提示找不到命令,则需要将python安装目录下的scripts加入到环境变量中。
如运行时发生import win32api 的error, 则需要安装pywin32 3 使用简介 === 使用scrapy 通常需要以下四个步骤:
- 新建工程(Project): 新建新的爬虫工程
- 定义目标 (Items): 确定需要从网页中获取的内容
- 生成爬虫(Spider): 定义爬取的url及爬取规则
- 保存内容(Pipeline): 保存处理爬取到的内容
3.1 新建工程
首先cd 到需要新建工程的目录下,然后执行:
scrapy startproject scrapy_testscrapy_test 是工程的名称,随后将创建一个scrapy_test目录,其目录格式如下:

各个目录及文件的作用如下所示:
scrapy.cfg:工程的配置文件
scrapy_test:工程的Python文件目录
scrapy_test/items.py:项目的items文件, 我们需要在此文件中定义需要从网页中获取的内容,对应上面说的步骤2
scrapy_test/pipelines.py:项目的pipelines文件, 用于保存处理爬取到的内容, 对应于步骤4
scrapy_test/settings.py:项目的设置文件
scrapy_test/spiders/:存储爬虫的目录, 对应步骤3
3.2 定义目标
这个步骤可以理解为确定我们需要从网页爬取的内容, 是需要爬取链接? 标题? 还是其他内容?
在scrapy 我们利用 “Item” 来代表保存爬取到的一条信息, 它可以包含多个内容, 具体的内容用”Field” 表示:
举个例子, 假定我们需要抓取 从 http://www.dmoz.org/Computers/Programming/Languages/Python/Books/
抓取每本书的标题, 链接和简单的描述, 那么我们在 scrapy_test/items.py 添加如下目标:
from scrapy.item import Item, Field
class DmozItem(Item):
title = Field()
link = Field()
desc = Field()可以把Item理解成更为安全的字典 , 而Field 则是字典里的内容.
定义完以上目标后, 我们可以将DmozItem 当成一般的字典操作:
>>> item = DmozItem()
>>> item['title'] = 'Example title'
>>> item['title']
'Example title'也很容易想到, 具体item里的内容,将由我们的Spider 获取并填充.
3.3 生成爬虫
前面的准备工作完成, 终于可以开始制作我们勤劳又能干的spider了
3.3.1 第一个Spider
Spider是用户定义的类, 用来获取特定域或者网站中指定的内容. 在爬虫里,我们定义了爬取的初始化的URL列表, 如何跟踪爬取到的新的link 及如何解析网页的内容填充我们前面定义的item.
Spider 都是从scrapy.Spider 派生, 并必须定义以下3个属性:
name: 用于标识每个spider, 同一工程内的spider的名字必须唯一.
start_urls: 定义了spider开始爬取的URL列表, Spider 将从这些定义的网页开始爬取
parse(): 爬虫的主要方法, 这个方法负责解析返回的URL数据, 匹配抓取到的数据填充Item, 并能跟踪更多的URL进行深入爬取.
我们还是来结合前面Item 定义的网页进行说明, 我们定义如下Spider:
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)我们将这个Spider命名为dmoz_spider.py, 并保存在scrapy_test/spiders 目录下.
这个Spider不具备解析数据功能, 我们只是用它来说明spider的结构, 并以此说明如何运行我们的Spider.
3.3.2 运行Spider
首先我们将当前目录变更为我们建立scrapy_test工程的目录(与scrapy.cfg 文件同级), 并运行: scrapy crawl dmoz
该命令将运行名为”dmoz” 的spider, 这个名字正是我们在前面DmozSpider定义的name, 然后我们将得到类似如下输出:
2014-11-05 17:28:37+0800 [scrapy] INFO: Scrapy 0.24.4 started (bot: scrapy_test)
2014-11-05 17:28:37+0800 [scrapy] INFO: Optional features available: ssl, http11
2014-11-05 17:28:37+0800 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': ..
...
2014-11-05 17:28:37+0800 [scrapy] INFO: Enabled spider middlewares: ..
2014-11-05 17:28:37+0800 [scrapy] INFO: Enabled item pipelines:
2014-11-05 17:28:37+0800 [dmoz] INFO: Spider opened
2014-11-05 17:28:37+0800 [dmoz] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2014-11-05 17:28:37+0800 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2014-11-05 17:28:37+0800 [scrapy] DEBUG: Web service listening on 127.0.0.1:6080
2014-11-05 17:28:39+0800 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/> (referer: None)
2014-11-05 17:28:39+0800 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Books/> (referer: None)
2014-11-05 17:28:39+0800 [dmoz] INFO: Closing spider (finished)
2014-11-05 17:28:39+0800 [dmoz] INFO: Dumping Scrapy stats:
......
2014-11-05 17:28:39+0800 [dmoz] INFO: Spider closed (finished)留意包含[dmoz] 的那些行, 这些log是我们的spider在爬取过程中产生的, ( 在我们的Spider里我们可以利用scrapy.log.msg 打印需要的信息)
这个Spider 的功能很简单, 运行完后, 我们发现在scrapy_test的顶层工程目录下生成了两个文件”Resources” 和 “Books” , 他们各自保存了start_urls 定义网页的html代码
Scrapy 为start_urls里定义的每个URL生成一个scrapy.Request对象, 然后指定parse方法为它们的回调函数;
在这些scrapy.Request对象发送并执行后, 将会返回scrapy.http.Response对象并通过parse方法传递给我们的spider.
要使上面的Spider 具备爬取指定内容的功能, 这就需要选择器Selector 出场了.
3.3.3 Selector选择器
Scrapy 使用的selector机制是基于 XPath 或者 CSS 表达式实现的. 其中XPath更易使用,因此本文仅介绍利用XPath进行数据提取.
如果你想了解更多selectors和其他机制你可以查阅资料 http://doc.scrapy.org/en/0.24/topics/selectors.html
下面列出了最有用的XPath表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| .. | 选取当前节点的父节点。 |
| . | 选取当前节点。 |
| @ | 选取属性。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
XPath example:
- /html/head/title: 选择HTML文档<head>元素下面的
标签。 - /html/head/title/text(): 选择前面提到的
元素下面的文本内容 - //td: 选择所有 <td> 元素
- //div[@class=”mine”]: 选择所有包含 class=”mine” 属性的div 标签元素
关于XPATH的介绍可以参考教程http://www.w3schools.com/XPath/default.asp
Scrapy提供了名为Selector类来对得到的response对象进行内容提取. 你可以将selector看成是xml 文档结构的某个节点, 第一个节点就是根节点.
Selector 提供以下4个基本方法:
- xpath(): 返回一系列selectors, 每一个selector代表了用xpath表达式选择的节点
- css(): 返回一系列selectors, 每一个selector代表了用css表达式选择的节点
- extract(): 返回selector提取到的数据的unicode字符串
- re(): 返回selector经正则表达式提取到的unicode字符串
为了测试selector, 我们使用scrapy 内建的Scrapy Shell 进行测试 (需要IPython 支持)
执行:
scrapy shell "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/"我们将得到:
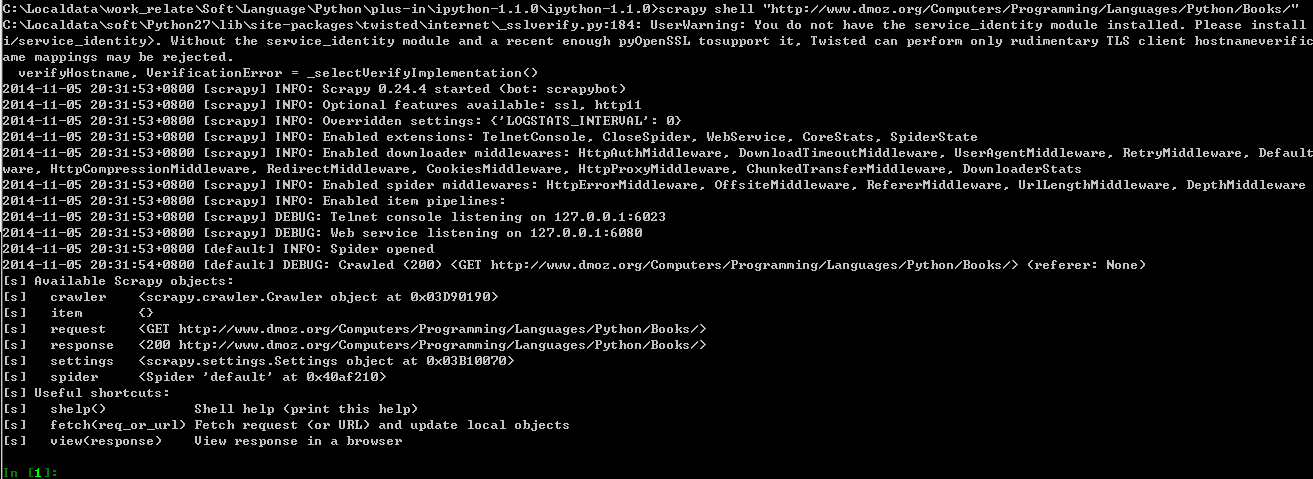 运行完这个命令后, 我们将得到获取自指定网页的response对象, 如果我们输入response.body将能看到返回的html代码.
运行完这个命令后, 我们将得到获取自指定网页的response对象, 如果我们输入response.body将能看到返回的html代码.
我们可以通过”response.selector”获得一个selector对象用于从而进行xpath或者css的查询.
为了方便输入, reponse.xpth和response.css直接映射到response.selector.xpath() 和 response.selector.css()
我们可以尝试以下xpath命令:
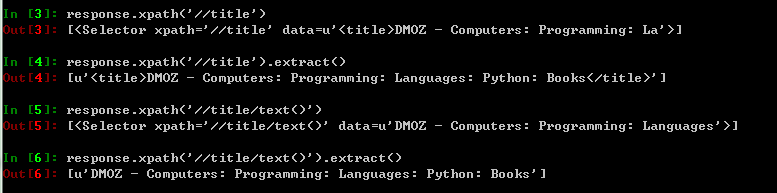
3.3.4 提取数据
到此我们可以利用selector使我们的spider具有数据提取的功能了
按之前举的例子, 我们需要抓取 从 http://www.dmoz.org/Computers/Programming/Languages/Python/Books/
抓取每本书的标题, 链接和简单的描述, 利用Chrome Developer Tools (F12) 或者其他的Xpath插件, 我们可以查询到这三项内容的html 规律是:
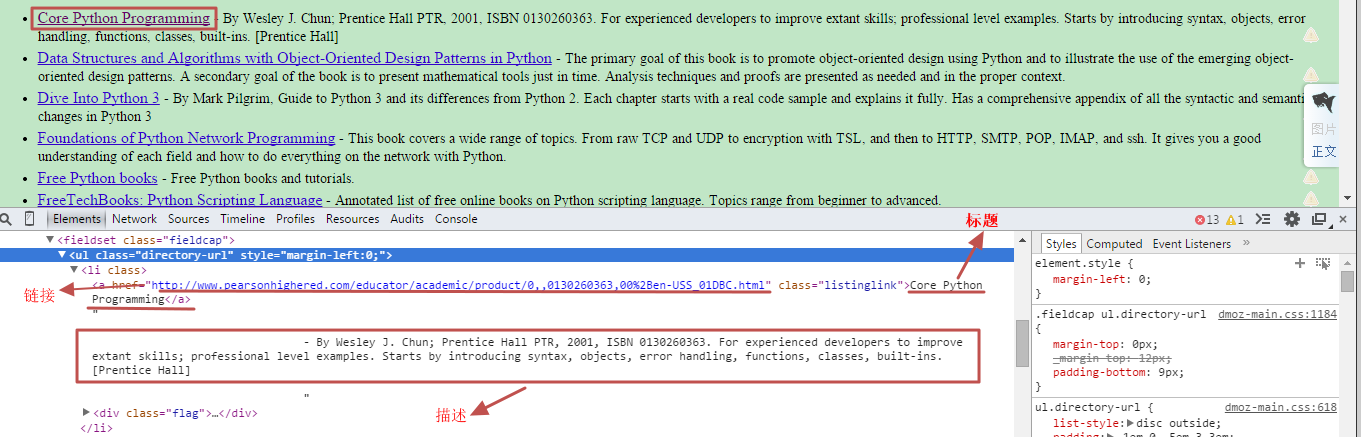
标题: 在以具有”class=directory-url”属性的<ul>为父节点的, <li>标签下,具有”class=listinglink”属性的<a>标签的内容
链接: 在以具有”class=directory-url”属性的<ul>为父节点的, <li>标签下,具有”class=listinglink”属性的<a>标签的href链接
描述: 在以具有”class=directory-url”属性的<ul>为父节点的, <li>标签的内容
因为这三项内容都是在<li>标签下, 因此提取公共部分:
sel = response.xpath(“//ul[@class=’directory-url’]/li”)
将上述规律转换成xpath 可得:
标题: title = sel.xpath(“a/text()”).extract()
链接: link = sel.xpath(“a/@href”).extract()
描述: desc = sel.xpath(“text()”).extract()
因此修改3.3.1的代码为:
import scrapy
from scrapy import log
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
for sel in response.xpath("//ul[@class='directory-url']/li"):
title = sel.xpath("a/text()").extract()
link = sel.xpath("a/@href").extract()
desc = sel.xpath("text()").extract()
print "title:" , title
print "link:" , link
print "desc:" , desc用 scrapy crawl dmoz 运行, 我们将能得到爬取到的信息.
3.3.5 使用 DmozItem
前面我们定义了Item, 现在我们可以在spider里填充我们的item了:
import scrapy
from scrapy import log
from scrapy_test.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
for sel in response.xpath("//ul[@class='directory-url']/li"):
item = DmozItem()
item['title'] = sel.xpath("a/text()").extract()
item['link'] = sel.xpath("a/@href").extract()
item['desc'] = sel.xpath("text()").extract()
yield item运行scrapy crawl dmoz , debug 信息说明我们已经抓取并填充成功:
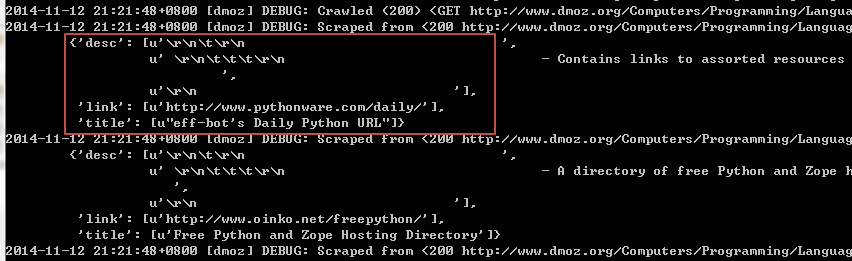
Scrapy 简单的使用我们就介绍到这里, 如果想更深入使用Scrapy, 可以参考官方文档:
睿初科技软件开发技术博客,转载请注明出处
blog comments powered by Disqus
发布日期
标签
最近发表
- volatile与多线程
- TDD practice in UI: Develop and test GUI independently by mockito
- jemalloc源码解析-核心架构
- jemalloc源码解析-内存管理
- boost::bind源码分析
- 小试QtTest
- 一个gtk下的目录权限问题
- Django学习 - Model
- Code snippets from C & C++ Code Capsule
- Using Eclipse Spy in GUI products based on RCP
文章分类
- cpp 3
- wxwidgets 4
- swt/jface 1
- chrome 3
- memory_management 5
- eclipse 1
- 工具 4
- 项目管理 1
- cpplint 1
- 算法 1
- 编程语言 1
- python 5
- compile 1
- c++ 7
- 工具 c++ 1
- 源码分析 c++ 3
- c++ boost 2
- data structure 1
- wxwidgets c++ 1
- template 1
- boost 1
- wxsocket 1
- wxwidget 2
- java 2
- 源码分析 1
- 网路工具 1
- eclipse插件 1
- django 1
- gtk 1
- 测试 1
- 测试 tdd 1
- multithreading 1