jemalloc源码解析-内存管理
发布者:
Renjian Qiu
前文对jemalloc的核心架构做了详细介绍, 本文重点分析jemalloc的内存管理。 jemalloc采用多级内存分配,引入线程缓存tcache, 分配区arena来减少线程间锁的争用, 提高申请释放的效率和线程并发扩展性。前面提到,jemalloc根据内存对象的大小把其分为small object, large object和huge object, 本文将分别介绍这些内存对象的申请和释放流程。
结构分析:
先介绍一下内存管理的层级结构:
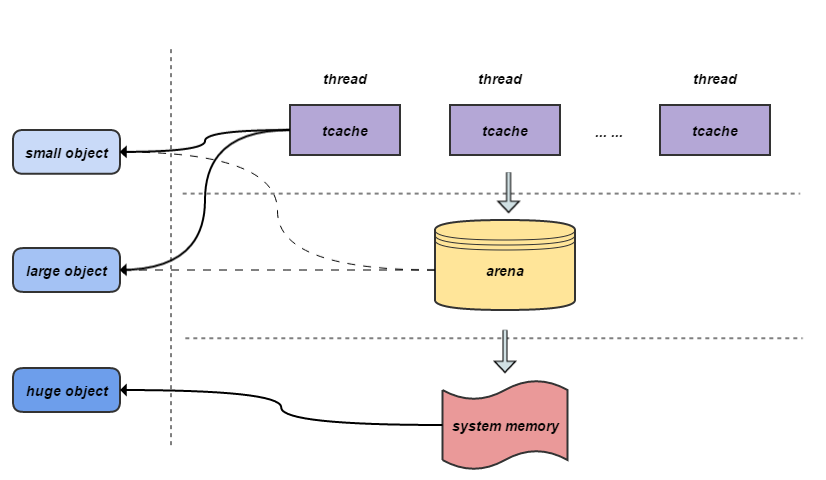
如图所示, jemalloc的内存管理采用层级架构, 分别是线程缓存tcache, 分配区arena和系统内存memory, 不同大小的内存块对应不同的分配区。每个线程对应一个tcache, 负责当前线程使用内存块的快速申请和释放, 避免线程间锁的竞争和同步。分配arena的具体结构在前文已经提到, 采用内存池的思想对内存区域进行合理的划分和管理, 在有效保证低内存碎片的情况下实现不同大小内存块的高效管理。 system memory是系统的内存区域。
- small object:当jemalloc支持tcache时, small object的分配从tcache开始, tcache不中则从arena申请run并将剩余区域缓存到tcache, 若从arena中不能分配再从system memory中申请chunk加入arena进行管理, 不支持tcache时, 则直接从arena中申请。
- large object: 当jemalloc支持tcache时, 如果large object的size小于tcache_maxclass,则从tcache开始分配, tcache不中则从arena申请, 只申请需要的内存块, 不做多余cache, 若从arena中不能分配则从system memory中申请。当large object的size大于tcache_maxclass或者jemmalloc不支持tcache时, 直接从arena中申请。
- huge object: huge object的内存不归arena管理, 直接采用mmap从system memory中申请并由一棵与arena独立的红黑树进行管理。
接下来我们基于代码进行详细介绍。
内存分配分析:
内存分配函数的入口位于:je_malloc/MALLOC_BODY/imalloc/imalloct
JEMALLOC_ALWAYS_INLINE void *
imalloct(size_t size, bool try_tcache, arena_t *arena)
{
assert(size != 0);
if (size <= arena_maxclass)
/*这里进行small object或large object的分配*/
return (arena_malloc(arena, size, false, try_tcache));
else
/*这里进行huge object的分配*/
return (huge_malloc(size, false, huge_dss_prec_get(arena)));
}这里把huge object的申请和其他对象进行的分流, 条件是arena_maxclass, 其中small object 和large object的分配需要通过tcache和arena进行分配, 如图:
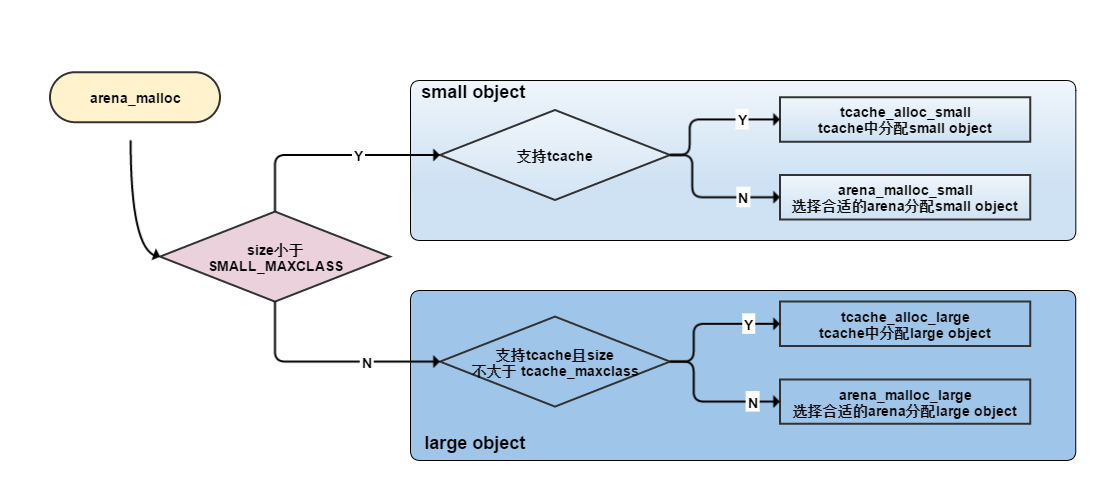
下面我们将分成以下几个部分介绍jemalloc内存分配:
- tache中分配small object
- arena中分配small object
- tache中分配large object
- arena中分配large object
- 分配huge object
这里我们先关注tcache中small object的分配, 这里主要要注意的是当tcache不中时, 需要调用arena_tcache_fill_small从arena中申请整块run进行分配, run剩余部分挂靠在tcache中使用。
JEMALLOC_ALWAYS_INLINE void *
tcache_alloc_small(tcache_t *tcache, size_t size, bool zero)
{
...
binind = SMALL_SIZE2BIN(size);
assert(binind < NBINS);
/*定位到对应的tbin*/
tbin = &tcache->tbins[binind];
size = arena_bin_info[binind].reg_size;
/如果tbin中有cache对象, 直接返回/
ret = tcache_alloc_easy(tbin);
if (ret == NULL) {
/*如果tbin对应cache为空, 则从对应arena中提取run填充cache并返回, 填充操作通过arena_tcache_fill_small完成*/
ret = tcache_alloc_small_hard(tcache, tbin, binind);
if (ret == NULL)
return (NULL);
}
...
}arena中small object的分配:
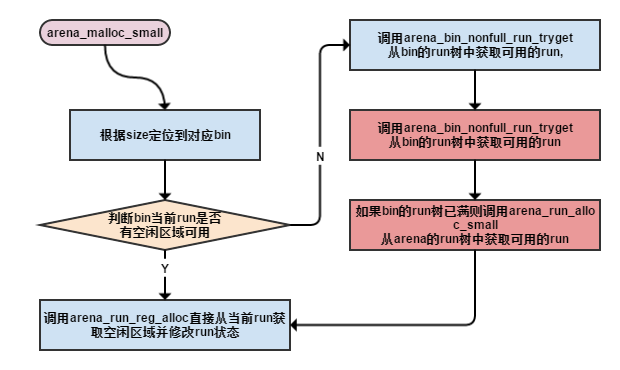
void * arena_malloc_small(arena_t *arena, size_t size, bool zero)
{
binind = SMALL_SIZE2BIN(size);
assert(binind < NBINS);
/*定位到arena中对应的bin*/
bin = &arena->bins[binind];
size = arena_bin_info[binind].reg_size;
malloc_mutex_lock(&bin->lock);
/*从bin取出一个可用的run进行内存块的分配中*/
if ((run = bin->runcur) != NULL && run->nfree > 0)
/*若bin中当前run中有空闲内存块可使用, 直接返回*/
ret = arena_run_reg_alloc(run, &arena_bin_info[binind]);
else
/*若runcur已满, 则从当前bin的runs(按地址排序的红黑树)中选择地址最低的可用run*/
ret = arena_bin_malloc_hard(arena, bin);
...
return (ret);
}arena中small object的分配涉及到run的管理和分配, 空闲的run红黑树顺序的调整已经run中bitmap状态的改变, 见下图:
tcache中large object的分配与small object的分配流程类似, 不同的是定位的tbin和处理cache不中的方法不同:
- 分配small object时, binind = small_size2bin[(s-1) » LG_TINY_MIN],在cache不中时, 会从arena得到多个small objects进行冗余cache。
- 分配large object时, binind = NBINS + (size » LG_PAGE) - 1, 在tcache不中时, 考虑到large object内存较大, 做冗余备份过于浪费, 只从arena申请一个对象。
JEMALLOC_ALWAYS_INLINE void *
tcache_alloc_large(tcache_t *tcache, size_t size, bool zero)
{
...
size = PAGE_CEILING(size);
assert(size <= tcache_maxclass);
binind = NBINS + (size >> LG_PAGE) - 1;
assert(binind < nhbins);
/*定位到对应的tbin*/
tbin = &tcache->tbins[binind];
/*如果对应的tbin中有cache对象,直接返回*/
ret = tcache_alloc_easy(tbin);
if (ret == NULL) {
/* 对应的tbin中无cache时, 直接从arena中申请一个large object, 不像small object一次申请多个做cache */
ret = arena_malloc_large(tcache->arena, size, zero);
if (ret == NULL)
return (NULL);
}
...
return (ret);
}arena中large object的分配较为简单, 不通过bin, 直接从对应chunk中申请相应大小的对象并通过run管理返回。
void * arena_malloc_large(arena_t *arena, size_t size, bool zero)
{
void *ret;
UNUSED bool idump;
/* Large allocation. */
size = PAGE_CEILING(size);
malloc_mutex_lock(&arena->lock);
/*arena中large object不通过bin进行管理, 直接从对应chunk中申请相应大小的对象并通过run管理返回。*/
ret = (void *)arena_run_alloc_large(arena, size, zero);
...
return (ret);
}所有的huge object通过一棵与arena独立的红黑树进行管理:
void *
huge_palloc(size_t size, size_t alignment, bool zero, dss_prec_t dss_prec)
{
...
/*构造一个红黑树节点来管理相应的large object*/
node = base_node_alloc();
if (node == NULL)
return (NULL);
/*申请足够的chunk并挂靠到前面的红黑树节点下面
*/
is_zeroed = zero;
ret = chunk_alloc(csize, alignment, false, &is_zeroed, dss_prec);
if (ret == NULL) {
base_node_dealloc(node);
return (NULL);
}
/* Insert node into huge. */
node->addr = ret;
node->size = csize;
malloc_mutex_lock(&huge_mtx);
/*把对应的红黑树节点插入红黑树*/
extent_tree_ad_insert(&huge, node);
...
return (ret);
}内存释放分析:
接下来介绍内存释放的过程, 刚好与内存申请对应,内存释放函数的入口位于:je_free/ifree/iqalloc/iqalloct/idalloct,
JEMALLOC_ALWAYS_INLINE void
idalloct(void *ptr, bool try_tcache)
{
arena_chunk_t *chunk;
assert(ptr != NULL);
/*基于small objec和large object的大小小于chunk,判断对象指针指向对类型 */
chunk = (arena_chunk_t *)CHUNK_ADDR2BASE(ptr);
if (chunk != ptr)
/*释放small object或large object*/
arena_dalloc(chunk->arena, chunk, ptr, try_tcache);
else
/*释放huge object*/
huge_dalloc(ptr, true);
}JEMALLOC_ALWAYS_INLINE void
arena_dalloc(arena_t *arena, arena_chunk_t *chunk, void *ptr, bool try_tcache)
{
...
if ((mapbits & CHUNK_MAP_LARGE) == 0) {
/* Small allocation. */
if (try_tcache && (tcache = tcache_get(false)) != NULL) {
size_t binind;
binind = arena_ptr_small_binind_get(ptr, mapbits);
/*tcache中释放small object*/
tcache_dalloc_small(tcache, ptr, binind);
} else
/*arena中释放small object*/
arena_dalloc_small(arena, chunk, ptr, pageind);
} else {
size_t size = arena_mapbits_large_size_get(chunk, pageind);
assert(((uintptr_t)ptr & PAGE_MASK) == 0);
if (try_tcache && size <= tcache_maxclass && (tcache =
tcache_get(false)) != NULL) {
/*tcache中释放large object*/
tcache_dalloc_large(tcache, ptr, size);
} else
/*arena中释放large object*/
arena_dalloc_large(arena, chunk, ptr);
}
}内存释放的流程刚好与内存分配对应起来, 根据对象的类型和来源的不同考虑不同的释放方法, 这里将分为以下几个部分介绍:
- tcache中释放对象
- arena中释放small object
- arena中释放large object
- 释放huge object
tcache中释放small object和large object的流程大致相同, 首先定位到对应的tbin, 如果当前tbin的缓存已满, 则调用tcache_bin_flush_xxx清除部分缓存, 然后把当前释放的object挂靠到缓存列表下面。
JEMALLOC_ALWAYS_INLINE void
tcache_dalloc_xxx(tcache_t *tcache, void *ptr, size_t size)
{
...
/*定位到tbin*/
tbin = &tcache->tbins[binind];
tbin_info = &tcache_bin_info[binind];
/*若cache满了则flush掉一半cache对象*/
if (tbin->ncached == tbin_info->ncached_max) {
tcache_bin_flush_xxx(tbin, binind, (tbin_info->ncached_max >>
1), tcache);
}
assert(tbin->ncached < tbin_info->ncached_max);
/*把要释放的对象插入bin对应cache数组,并更新数据*/
tbin->avail[tbin->ncached] = ptr;
tbin->ncached++;
}arena中small object的释放:arena_dalloc_small/arena_dalloc_bin/arena_dalloc_bin_locked:
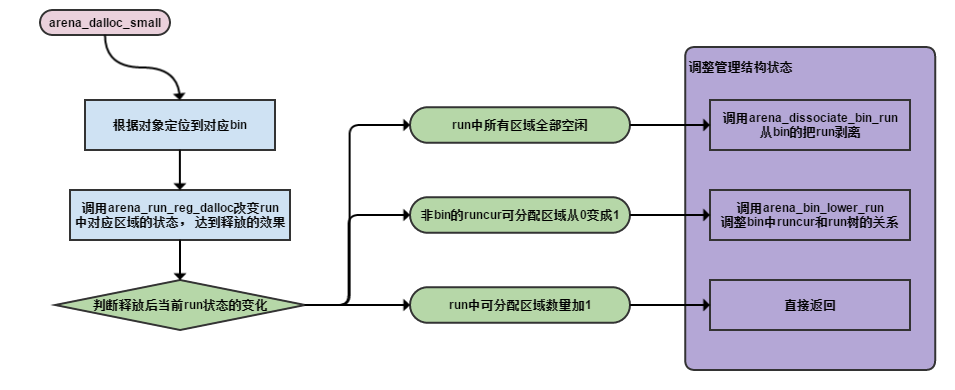
void
arena_dalloc_bin_locked(arena_t *arena, arena_chunk_t *chunk, void *ptr,
arena_chunk_map_t *mapelm)
{
...
pageind = ((uintptr_t)ptr - (uintptr_t)chunk) >> LG_PAGE;
/*定位到对应的run*/
run = (arena_run_t *)((uintptr_t)chunk + (uintptr_t)((pageind -
arena_mapbits_small_runind_get(chunk, pageind)) << LG_PAGE));
bin = run->bin;
binind = arena_ptr_small_binind_get(ptr, mapelm->bits);
bin_info = &arena_bin_info[binind];
...
/*改变run内部对应分配区域的状态*/
arena_run_reg_dalloc(run, ptr);
/*针对run状态的变化对bin进行调整*/
if (run->nfree == bin_info->nregs) {
/*run有只是用一个到变空的状态变化*/
arena_dissociate_bin_run(chunk, run, bin);
arena_dalloc_bin_run(arena, chunk, run, bin);
} else if (run->nfree == 1 && run != bin->runcur)
/*run由full变成空闲一个的状态变化*/
arena_bin_lower_run(arena, chunk, run, bin);
...
}arena中small object的释放和申请一样会造成所在run空闲状态的变化, 进而导致对应bin和arena结构的调整,稍微复杂一些, 如图:
arena的largel object的释放跟bin没有关系, 只需要把占用的内存页还给arena并更新arena的状态就可以:arena_dalloc_large/arena_dalloc_large_locked:
void arena_dalloc_large_locked(arena_t *arena, arena_chunk_t *chunk, void *ptr)
{
/*更新arena的run的状态*/
arena_run_dalloc(arena, (arena_run_t *)ptr, true, false);
}huge object的释放就是红黑树的删除节点的操作并释放相关内存。
void huge_dalloc(void *ptr, bool unmap)
{
...
/* Extract from tree of huge allocations. */
key.addr = ptr;
/*找到对应红黑树节点*/
node = extent_tree_ad_search(&huge, &key);
assert(node != NULL);
assert(node->addr == ptr);
/*从红黑树中删除节点*/
extent_tree_ad_remove(&huge, node);
...
/*释放相关内存*/
chunk_dealloc(node->addr, node->size, unmap);
base_node_dealloc(node);
}小结:
jemalloc的内存分配就介绍完毕, 这里做一个简单的总结:
- jemalloc引入线程缓存tcache, 分配区arena来减少线程间锁的争用, 保证线程并发扩展性的同时实现了内存的快速申请释放
- 采用arena管理不同大小的内存对象在保证内存高效管理的同时减少了内存碎片
- 引入红黑树管理空闲run和chunk, 相比链表具有了更高的效率
- 在run中采用bitmap管理可分配区域来实现管理和数据分离, 且能够更快地定位到空闲区域
- 引入了多层cache, 基于内存池的思想, 虽然增加了内存占用, 但实现了内存的快速申请释放, 除了tcache,还有bin中的runcur, arena中的spare等。
参考文献:
A Scalable Concurrent malloc(3) Implementation for FreeBSD
Scalable memory allocation using jemalloc
睿初科技软件开发技术博客,转载请注明出处
blog comments powered by Disqus
发布日期
标签
最近发表
- volatile与多线程
- TDD practice in UI: Develop and test GUI independently by mockito
- jemalloc源码解析-核心架构
- jemalloc源码解析-内存管理
- boost::bind源码分析
- 小试QtTest
- 一个gtk下的目录权限问题
- Django学习 - Model
- Code snippets from C & C++ Code Capsule
- Using Eclipse Spy in GUI products based on RCP
文章分类
- cpp 3
- wxwidgets 4
- swt/jface 1
- chrome 3
- memory_management 5
- eclipse 1
- 工具 4
- 项目管理 1
- cpplint 1
- 算法 1
- 编程语言 1
- python 5
- compile 1
- c++ 7
- 工具 c++ 1
- 源码分析 c++ 3
- c++ boost 2
- data structure 1
- wxwidgets c++ 1
- template 1
- boost 1
- wxsocket 1
- wxwidget 2
- java 2
- 源码分析 1
- 网路工具 1
- eclipse插件 1
- django 1
- gtk 1
- 测试 1
- 测试 tdd 1
- multithreading 1