ASSummary 实现设计与分析
发布者:
Jeremy
ASSummary 实现设计与分析
一 ASSummary介绍
我们AS Team 有一个内部统计网站ASSummary (公司内网),它用来统计我们在BrionCD和 Reviewboard中的各种数据。BrionCD 是基于开源问答系统OSQA实现的,它是我们内部的Q&A网站,我们可以在其中提问和回答工作中遇到的各种问题,你的提问很快能得到“专家”同事的回答,效率和质量甚至比stackoverflow还赞;而Reviewboard是我们使用的基于代码web代码审查工具,对我们的代码质量控制具有重要作用,详细使用可以参考官方使用文档。
ASSummary使得我们能方便的获得这两个独立网站的各种统计数据,例如:在Reviewboard中有多少提交代码没有被“Shiped”(代码已被其他人审查),有多少指定让你审查的代码,或者你在review过程中做了多少注释;又或者在BrionCD中哪个tags的问题最多,最近大家分享了哪些好文章。这些数据有助于提高团队的工作效率,同时对个人技术能力培养同样具有参考作用。先列出本文会讨论分析的内容:
- 一 ASSummary介绍
- 二 ASSummary实现框架
- 三 How To实现
- 3.1 部署App到Apache
- 3.2 ASSummary响应过程
- 3.3 添加可排序表格
- 3.4 定时发送邮件
- 四 总结
二 ASSummary实现框架
基于以上需求的统计网站不需要很复杂的功能, 它主要是从BrionCD及Reviewboard的MySQL数据库中获取我们需要的数据, 然后汇总显示出来就可以了。有很多web框架(Django,Tornado等)可以轻松胜任,但是对于我们的统计网站的要求,使用他们就有种杀鸡用牛刀的感觉。因此最终我们选择用Bottle这个轻量级web框架实现我们的网站。Bottle是一个非常小巧但高效的微型 Python Web 框架,它的实现仅仅依靠只有一个文件的Python模块,并且除Python标准库外,它不再依赖于任何第三方模块。Bottle的学习及使用,相当简单,这里不多说,大家可以参考官方教程。本文主要是介绍我们ASSummary的实现过程,及其中遇到的一些问题。
下图是整个ASSummary的基本架构图。
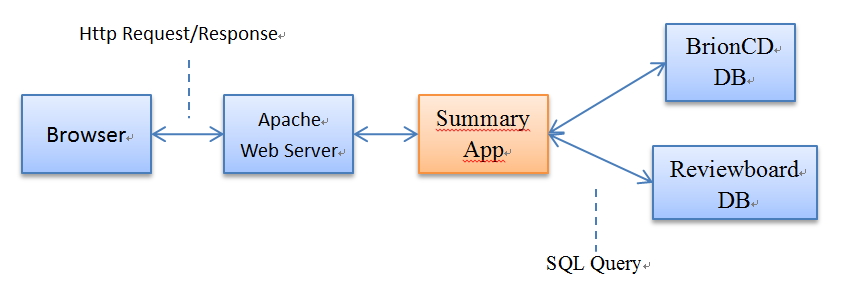
从框架图我们可以看出, 我们用Apache作为我们的Http Server服务器,同时将Summary App部署为其中的一个WSGI模块,用于响应用户不同的统计查询请求。Summary App就是基于Bottle写的简单App,只需要两个文件实现(summary.py及base.tpl,稍后会详细介绍),它主要功能就是根据用户输入的不同URL, 对BrionCD或Reviewboard的数据库进行相应查询,然后将查询结果用base.tpl 这个模板文件“包装”并返回给浏览器,这样用户就可以在ASSummary的网页方便浏览各种统计数据了。
接下来,我们会对ASSummary的实现过程,及遇到的问题作出详细说明,希望以后对大家维护ASSummary或进行类似web应用开发具有一定参考作用。
三 How To实现
3.1 部署App到Apache
我们需要在Apache Web Server中通过mod_wsgi将Summary 部署为其中的一个App。首先在Apache服务器的配置文件httpd.conf中添加以下ASSummay的配置信息:
<VirtualHost *:8880> ------------------------ 端口
ServerName brioncd.briontech.com ------------------------ 访问域名
WSGIDaemonProcess ASSummary ----------------------- WSGI后台进程名
WSGIScriptAlias / /srv/www/ASSummary/app.wsgi --------------- App 脚本文件
<Directory /srv/www/ASSummary> ------------------------- 网站主目录
WSGIProcessGroup ASSummary
WSGIApplicationGroup %{GLOBAL}
Order deny,allow
Allow from all
</Directory>
</VirtualHost>
从这个配置文件我们可以看到ASSummary网站的域名、端口及其主要的App脚本文件等信息,正确配置这些信息后才能使我们的网站顺利被访问到。 接下来我们再来看看app.wsgi这个App脚本文件:
import os, sys
os.chdir(os.path.dirname(__file__))
wsgi_dir=os.path.dirname(__file__)
sys.path =[wsgi_dir]+ sys.path
import bottle
import summary
application = bottle.default_app()
它首先将app.wsgi所在的目录加入到系统path目录中,然后启动bottle默认app。这个目录下具有我们网站所需的所有文件,我们一起看看目录下都有哪些主要文件:

Static 文件夹用于存放于网站相关的css,image及一些Jscript文件。
app.wsgi 是上面介绍的应用脚本文件。
bottle.py 是我们使用的bottle框架仅仅需要的文件,够微型吧J
base.tpl 是我们ASSummary网站的模板文件,使用了bootstrap的模板,里面的大部分模板都简洁而清新,很适合些功能简单的小网站使用。我们需要根据具体需求,需要修改这个模板文件,查询数据就是“塞”到这个模板里。这个模板使用也很简单,代码中仅需要通过open(‘base.tpl’) 及 bottle提供的template功能就可实现调用。下面会介绍。
summary.py 我们主要需要编写的code就在这个文件里,它的功能是对不同URL请求,对BrionCD或Reviewboard的数据库进行相应查询,然后返回不同的查询结果,接下来我们会对这个过程进行详细介绍。
这里只列出浏览ASSummary相关的文件,还有些文件与其他功能相关(如定时自动发送统计邮件),我们暂不列出,将在后面的文档对该功能进行介绍。
3.2 ASSummary响应过程
summary.py是整个网站的“核心”,处理用户浏览请求,对不同URL作出不同的数据库查询,得到查询结果再返回页面给用户。下面我们将以用户访问ASSummary首页为例, 对整个响应流程及相应代码作出介绍。
首先,我们在summary.py中有许多类似以下的代码,它定义了ASSummary不同的URL请求响应。
@route('/')
@route('/osqa/')
@route('/count_ask/')
def count_ask():
sql = '''
select au.username, count(fa.id) as ask_count, au.email from forum_action as
fa, auth_user as au where fa.action_date %s and
fa.action_type='ask' and fa.user_id=au.id group by au.username
order by ask_count desc;'''
return connect_and_render('osqa', sql, 'count_ask', True)
从代码我们可以看出在访问http://brioncd.briontech.com:8880/ 、http://brioncd.briontech.com:8880/osqa/ 及http://brioncd.briontech.com:8880/count_ask/ 都会路由到count_ask这个函数执行。这个函数功能很简单,就是定义一条SQL查询语句,然后执行connect_and_render这个函数,我们来看看这个函数具体功能。
def connect_and_render(db_name, sql, url, has_query, filter = None, need_login= False):
''' get rows and render template '''
rows = []
if has_query:
date_query, message, the_date = get_date_query(request)
if not sql == "":
sql = sql % date_query
rows = connect_and_get(db_name, sql, filter)
return template(_TPLT, rows = rows, title = url2title(url),
the_date = the_date, has_query = True,
message = message, nav_bar = get_nav_bar(url, db_name), db_name = db_name, need_login = need_login, as_member_mails_map = as_member_mails_map)
else:
if not sql == "":
rows = connect_and_get(db_name, sql)
return template(_TPLT, rows = rows, title = url2title(url), message = '',
nav_bar = get_nav_bar(url, db_name), db_name = db_name, has_query = False, need_login = need_login, as_member_mails_map = as_member_mails_map)
先来看看函数的参数:
db_name: 选择使用的db名称,“osqa”表示查询BrionCD数据库,“reviewboard”表示查询reviewboard数据库
sql:查询数据库需要执行的SQL查询语句,根据不同URL编写不同的SQL语句
url:访问的URL,这个会传递到模板文件中,决定页面显示。
has_query:是否具有请求,具有请求的页面会有如下的表单,可供用户输入查询时间等信息。

filter:定义SQL查询结果的过滤条件,lambda表达式
need_login:这个条件只有在第一次访问/document 页面时,需要设置为True,这时会弹出一个下拉框用于选择用户名,然后将此用户名保存为cookie,因为bottle框架不具有用户注册登录功能, 所以以这种方式获取用户信息。
从代码我们可以看到,如果has_query为True,则会首先执行get_date_query函数获取表单发送的数据。这个数据通常包含查询时间范围的信息如“?year=2014&month=3&month_end=3&week=”。获取到查询时间后,我们将这个查询时间转换为SQL的时间格式,然后通过sql= sql % date_query 将查询条件格式化到原本写好的sql语句中。
然后执行connect_and_get链接DB并执行SQL语句,在得到查询结果后我们将查询数据等信息传递到打开的base.tpl模板文件中。在这个模板文件中嵌入了python语句,会对传入的不同参数进行判断,从而在同一份模板文件中显示出不同的页面信息。最后再将经过模板文件“包装”过后的数据,返回给用户即完成了整个访问流程。下面是这个过程的流程图:
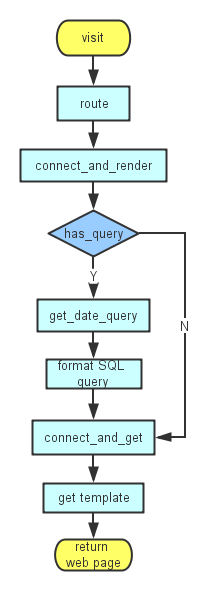
从这个流程我们看出,ASSummary的响应过程是比较清晰简单的,针对不同的URL路由选择不同的SQL查询语句,然后利用传入模板的参数,修改返回页面模板供用户浏览。因此,维护及完善ASSummary的主要任务就需要编写SQL查询语句及修改模板base.tpl文件。
3.3 添加可排序表格
对于某些统计数据表格,我们需要为其添加排列功能,如以下文档统计页面,它是用来统计指定时间范围内,组内成员原创或转载的文档, 它具有5列分别显示:你对文档的投票状态、文档日期、文档submitter、文档链接、文档投票得分。

不同情况下,我们可能需要根据不同的要求对表格数据进行排列。这些统计数据是由我们查询BrionCD数据库得到的,默认是根据文档post时间降序排列。因此为了实现这个功能首先最直接想到的实现方法是,在页面上添加一个select控件,然后列出排列的key供用户选择,根据key修改SQL语句排列顺序。但是这样实现会具有很多问题,首先最问题是每次重新排列都需要查询数据库,刷新页面,这样效率比较低;而且假设以后添加修改文档统计列,还必须记得修改这个select控件,维护成本高。
然后,想到的是利用JavaScript, 在Google下搜索“javascript table sort”排在第一位的是一个叫“tablesorter”的jQuery插件。看了下它的简介,Good! 这就是我们想要的,不需要重新查询数据库,不需要添加额外控件,使用也极为简单。仅需要以下几个简单步骤,即可为所有Table添加排序功能,居家旅行制作网页必备插件啊:
1.下载并加载jQuery,因为我们用的模板已经安装了jQuery所以这步我们省略了。
2.下载并在base.tpl模板文件中通过以下Javascript语句加载tablesorter插件:
<script type="text/javascript" src="/path/to/jquery.tablesorter.js"></script>
3.在需要排列功能的Table的class添加“tablesorter”:
<table class="tablesorter" id="table_data">
<thead>
...
</thead>
</table>
4. 在base.tpl模板文件中使能Table排列。
$(document).ready( function() {
$("#table_data").tablesorter();
});
在添加排列功能后的统计页面如下图所示,
我们可以通过点击每列的列名对表格进行顺序或降序排列。

3.4 定时发送邮件
我们需要ASSummary能定时自动发送统计信息如:每天发送reviewboard统计数据,提醒大家还有多少代码没被别人review,自己又还有多少代码要帮别人review;同时每周一将上周组内原创和分享的文章发送给大家,方便阅读,及对好文章进行投票加分。
要实现这类功能有很多办法,一个简单的办法就是利用我们Server机器Linux系统提供的内置定时服务Cron。
关于Cron的使用这里不做介绍,大家可以参考wiki说明。下面只介绍我们是如何利用Cron服务,将我们的统计信息发送到组内成员邮箱的。
首先,编辑Cron的配置文件/etc/crontab,添加如下画线部分内容。从这个配置文件的注释,我们也很容易理解添加这行语句的含义:
每周1到5,早上9点35分,cd到/srv/www/ASSummary
,并执行reviewboardmail.py这个python脚本。
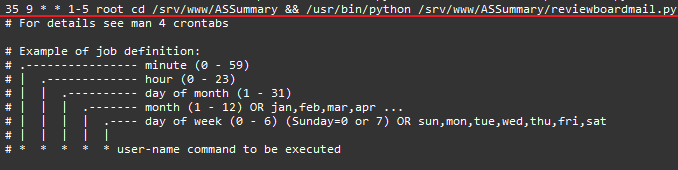
显然这个reviewboardmail.py脚本就是将统计信息发送邮箱的脚本,它主要包含两部分功能:获取统计信息和发送邮箱。
首先,如何获取需要发送的统计信息呢?
类似前面介绍的访问ASSummary网页的流程,我们可以直接从相关数据库中通过SQL查询获取,执行与访问网页类似的查询过程。但是这样就意味着,在这个reviewboardmail.py脚本中,也存在一份类似summary.py的SQL语句,这样也给将来的维护带来不便。
其实我们已经有一个很好的数据获取来源,那就是我们的ASSummary网站本身。只要通过一个简单的网页爬虫,就可以将我们需要的统计数据获取到,下面给出获取数据的主要代码块:
def get_table_row(link):
……
sock = urllib.urlopen(link)
summary_parser = ASSummaryTableParser()
link_html = sock.read()
sock.close()
summary_parser.feed(link_html)
……
return rows_count,table_html
get_table_row这个函数传入我们需要获取统计信息的ASSummary网址,然后通过urllib获取网页的html,再将网页html代码“feed”到我们的ASSummaryTableParser这个解析器中,通过parser获取网页中的统计数据,然后加上必要的html代码返回。这个Parser是HTMLParser的子类,HTMLParser的使用可以参考官方说明文档。我们使用的Parser代码也很简单,就是主要获取网页html中table的每行数据。
class ASSummaryTableParser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.is_table = False
self.is_tr = False
self.is_td = False
self.rows = []
self.element = []
def handle_starttag(self, tag, attrs):
if tag == "table":
self.is_table = True
del self.rows[:]
if self.is_table:
if tag == "tr":
self.is_tr = True
del self.element[:]
if self.is_tr == True:
if tag == "td":
self.is_td = True
def handle_endtag(self, tag):
if tag == "td":
if self.is_td:
self.is_td = False
if tag == "tr":
if self.is_tr:
self.is_tr = False
row = copy.copy(self.element)
self.rows.append(row)
def handle_data(self, data):
if self.is_td:
self.element.append(data)
获取完数据,我们就可以将获取的数据用一个模板文件assummarymail.tpl将统计数据“包装”起来,这样我们发送的邮件才不至于太过简陋。这里模板包装的方法,类似前面介绍的bootle的Template方法,但是这里使用的仅仅是python内置的string模块的Template方法,不再介绍。
在获取“包装”完的统计内容后,我们即可将内容邮件发送。这里邮件发送使用的是python的smtplib及email两个module,网上有好多类似的使用例程,这里直接给出代码:
def send_mail(to_list, cc_list, sub, content):
'''
to_list: receiver list
to_list: cc list
sub: mail subject
content: mail content
send_mail("aaa@126.com","bb@126.com","sub","content")
'''
me = "AS Summary<assummary-noreply@brioncd.briontech.com>"
msg = MIMEText(content, 'html', 'utf-8')
msg['Subject'] = sub
msg['From'] = me
msg['To'] = ";".join(to_list)
msg['Cc'] = ";".join(cc_list)
try:
s = smtplib.SMTP()
s.connect(mail_host)
s.sendmail(me, to_list, msg.as_string())
s.close()
return True
except Exception, e:
print str(e)
return False
这样我们就完成了整个获取统计信息,并定时发送邮件的过程。
四 总结
虽然这个ASSummary统计网站功能比较简单,但是其中涉及的知识还是比较丰富的:bottle框架,SQL数据库,CSS,Javascript,jQuery,模板等,可谓“麻雀虽小,却五脏俱全”,在这学习过程中让我收获颇分。因为这其中很多知识和技术,以前也没有接触过,属于现学现卖,所以难免会出现一些错漏,如有发现可邮件至:jeremy.peng@asml.com。同时希望这篇文档能给后来的ASSummary维护者 ,或欲制作类似网站的人,带来一定的参考意义,谢谢!
睿初科技软件开发技术博客,转载请注明出处
blog comments powered by Disqus
发布日期
标签
最近发表
- volatile与多线程
- TDD practice in UI: Develop and test GUI independently by mockito
- jemalloc源码解析-核心架构
- jemalloc源码解析-内存管理
- boost::bind源码分析
- 小试QtTest
- 一个gtk下的目录权限问题
- Django学习 - Model
- Code snippets from C & C++ Code Capsule
- Using Eclipse Spy in GUI products based on RCP
文章分类
- cpp 3
- wxwidgets 4
- swt/jface 1
- chrome 3
- memory_management 5
- eclipse 1
- 工具 4
- 项目管理 1
- cpplint 1
- 算法 1
- 编程语言 1
- python 5
- compile 1
- c++ 7
- 工具 c++ 1
- 源码分析 c++ 3
- c++ boost 2
- data structure 1
- wxwidgets c++ 1
- template 1
- boost 1
- wxsocket 1
- wxwidget 2
- java 2
- 源码分析 1
- 网路工具 1
- eclipse插件 1
- django 1
- gtk 1
- 测试 1
- 测试 tdd 1
- multithreading 1