LevelDB learning
发布者:
Xuan Zhou
1.简介
levelDB是Jeff Dean和Sanjay Ghemawat发起的开源key-value DB,支持读、写、删除这些基本功能,也支持快照(通过log file),数据压缩(snappy compress)。目前有一些开源的数据库是基于levelDB实现的,比如,Tair ldb以及SSDB
levelDB的读写性能很好,参考官方benchmark数据(由于使用了cache,顺序读性能优于随机读)。比较适用于随机写操作密集或是顺序读较多的情况
1.1 levelDB用法
源代码: leveldb-1.15.0
levelDB的使用:
tar xvf FileName.tar leveldb-1.15.0
cd leveldb-1.15.0
make就会在目录中生成libleveldb.a及libleveldb.so, 一个例子:
#include <iostream>
#include "leveldb/db.h"
int main()
{
leveldb::DB* db;
leveldb::Options options;
options.create_if_missing = true;
leveldb::Status status = leveldb::DB::Open(options, "/home/xuzhou/leveldb-1.15.0/test/testdb", &db);
// put test
char numStringPut[64];
for (int i = 0; i < 10000; ++i)
{
sprintf(numStringPut, "%d" , i);
std::string keyPut(numStringPut);
std::string valuePut = keyPut;
status = db->Put(leveldb::WriteOptions(), keyPut, valuePut);
assert(status.ok());
}
// get test
char numStringGet[64];
for (int i = 0; i < 10000; ++i)
{
sprintf(numStringGet, "%d" , i);
std::string keyGet(numStringGet);
std::string valueGet;
status = db->Get(leveldb::ReadOptions(), keyGet, &valueGet);
assert(status.ok());
std::cout << "keyGet:" << keyGet << " valueGet:" << valueGet << std::endl;
}
// delete test
char numStringDelete[64];
for (int i = 0; i < 10000; ++i)
{
sprintf(numStringDelete, "%d" , i);
std::string keyDelete(numStringDelete);
status = db->Delete(leveldb::WriteOptions(), keyDelete);
assert(status.ok());
}
delete db;
return 0;
}编译运行:
bash-3.00$ g++ -o test -g main.cpp -lpthread -L./ -lleveldb -I/home/xuzhou/leveldb-1.15.0/include
bash-3.00$ ./test
bash-3.00$ pwd
/home/xuzhou/leveldb-1.15.0/test/testdb
bash-3.00$ ls
000003.log CURRENT LOCK LOG MANIFEST-0000021.2 与其它数据库比较
1.2.1 Redis vs levelDB
| Redis | levelDB | |
|---|---|---|
| 相同点 | 持久化存储 | |
| 写速度快 | ||
| 不同点 | 完全内存查找,速度快 | 随机查找性能差,可能产生磁盘IO,速度较慢 |
| value类型不仅限于字符串(字符串列表,无序不重复的字符串集合,有序不重复的字符串集合,key和value都为字符串的hash表 | key-value均为字符串,可自定义Comparator | |
| 多语言支持 | 一个C++库 | |
| 存储容量受限于内存,磁盘只作为备份 | 存储容量依赖硬盘,可支持TB级别数据 | |
1.2.2 sqlite vs levelDB
- b+ tree vs lsm tree
- sql vs nosql
- 性能比较: 官方benchmark数据
2.整体结构
2.1 LSM tree
b+ tree是各种传统db及磁盘索引结构,它的缺点在于每次写操作都可能带来多次的磁盘IO(磁头的旋转和寻道都很耗时,所以顺序读写性能都会优于随机读写),写开销很大,怎样避免磁盘IO呢,LSM tree(Log-Structured Merge-Tree)就是为了优化磁盘写的一种存储结构, 是由The Log-Structured Merge-Tree 提出的,主要是通过将随机写操作转换为内存写和log追加,再批量写入磁盘。levelDB就是基于这种存储结构实现的。
2.2 levelDB的整体结构
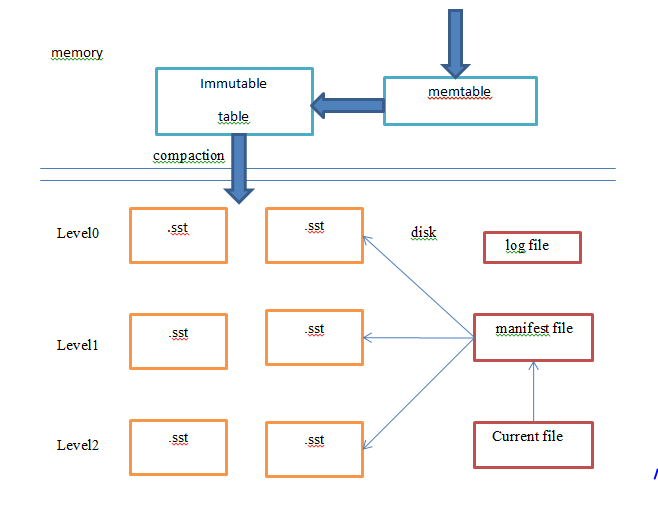
其中:
内存中的结构:
- memtable: 是内存中的一个跳表结构。当用户向levelDB中写入数据时,会先向log file中写入一条log记录,然后将这个key-value插入跳表中(为什么要使用跳表,后面会介绍)
- immutable table:正在进行compact的memtable。当memtable的占用的内存到达write_buffer_size,就会将这个memtable变为immutable table,并重新生成新的memtable和log file
磁盘中的结构
- level0: 这个level比较特殊,其中的每个文件都是对immutable table进行compaction生成的,每个文件内部都是由一些有序key-value record组成的block的集合,但是文件和文件之间是无序的,可能有重叠(为什么需要这个特殊的的level)
- level1~levelN:这些level的结构比较相似,每层level里也是一些key-value有序的sst file,但是同一层的sst file之间也是有序的,所以在同一层的sst files之间不存在重叠的key-value,其中levelK的总容量为10^K,但每个文件大小都是2M
- log file: 用于记录DB操作,用于恢复还没有写入磁盘的memTable, immutable table操作,保证数据一致性。文件名中含有log num,必须保证每次新建的log file的log num最大,以此保证log num最大的log file是最新的
- manifest file: log文件,由若干条记录组成(快照+若干条version_edit信息),每次进行compaction后,就会进行version更新,manifest就会将记录version中文件的变化等信息作为一条record写入文件。当需要文件恢复时,通过当前manifest文件的所有record就能获得当前所有level的信息,再通过读log文件,就能恢复memTable, immutable table的信息
- current file: 指向当前version的manifest file
3.文件结构
3.1 背景知识
- slice:是levelDB中最基本的结构,和string类似,包括一个指向字符串的指针及其长度,主要包含一些字符串操作的函数:
const char* data_;
size_t size_;-
status: levelDB中的消息传递类
-
Arena: 一个比较简单的内存池,为memtable分配内存
-
skip list: memtable的主要结构(线程安全),进行逻辑删除,只对删除的key-value做标记,在compaction的时候才进行删除记录。其查找,插入及删除(只进行逻辑删除)的复杂度都为logN,同时实现比平衡二叉树简单很多,而且用概率的方式平衡性更好。具体细节可以参考:Skiplist vs Non-blocking
-
Varint:不定长整数,每个byte中最高用来标记是否结束,其余7位用来表示数字,最高为0,表示该bit为整数的最后一个byte
3.2 memTable结构
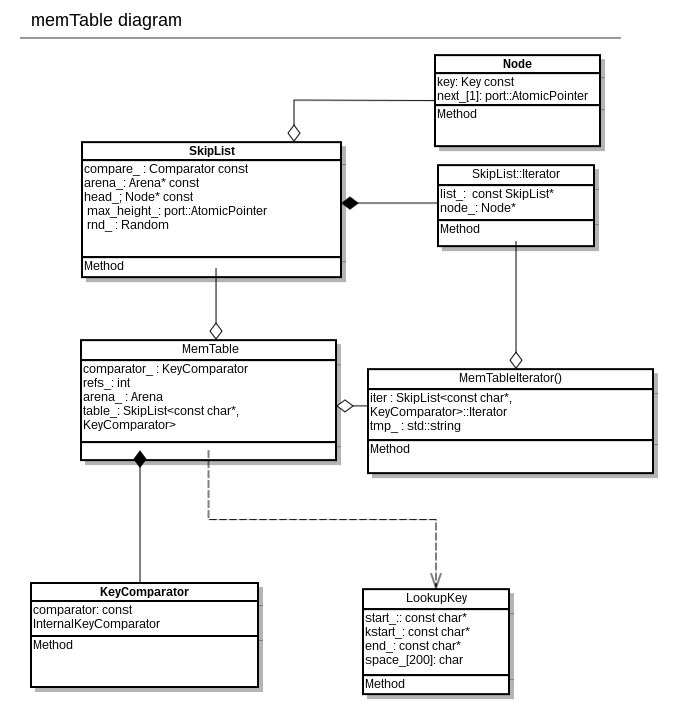
在levelDB中,用户输入的key-value中的key会与SequenceNumber及ValueType构成InternalKey, InternalKey是levelDB中用于比较索引的key, 每个InternalKey都是唯一的

其中:
- user_key: 用户输入的key字符串
- SequenceNumber: 一个64位整数,这个整数根据entry插入的时间顺序递增,可以认为是entry的时间戳,当user_key相同时, InternalKey以SequenceNumber降序递增
- ValueType: entry的操作类型,kTypeDeletion(删除), kTypeValue(插入)
而插入skiplist的entry结构为:

3.3 .sst file(data block)
.sst file的整体结构如图所示:
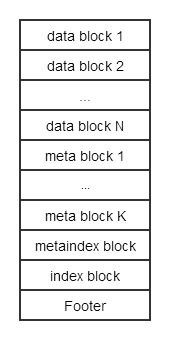
在这个版本里meta_block只用于存放filter的数据,可能在以后的版本中增加更多其它类型的数据
其中,data_block, index_block以及metaindex_block都以key-value组成block的形式存放所有数据。meta_block中存放的是filter
Footer是文件的结尾,其结构为:

handle中存放的是offset及size,那么根据footer就能找到metaindex_block以及index_block的位置
index_block中key为data_block的last_key(查找时就能通过index_block定位key所在的data_block), value为data_block_handle
metainde_block中key为meta_name, value为meta_block_handle
因此,在查找时sst文件的读取顺序为Footer->index_block(二分查找)->meta_block(filter,快速查找)->data_block
为了减小存储容量,TableBuilder会对这些不同类型的block进行压缩(option,压缩和解压缩的过程会降低levelDB的读写速率),并加入校验码(保证数据的正确性),形成的block结构为

其中type表示是否进行压缩
而data_block, index_block以及metaindex_block的具体结构为:
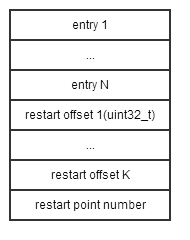
每个block中会有若干个restart_point,restart_offset存放了这些restart point的offset,由于block中存放的entry都是有序的,那么根据restart_offset的到的restart_point也是key有序的,那么就可以通过二分查找定位key是存放在哪两个start_point之间的。但是在两个start_point之间除了start_point之外的entry的key都是依赖于上一条entry的key, 因此两个start_point之间的查找都是顺序查找。
每条entry的结构为:

shared_bytes == 0的位置表示restart_point, entry中的key都只保存和上一个key不同的部分,相同的部份只通过shared_length从上个key中获取(相当于对key进行了压缩,主要也是为了节省存储空间)
3.3.1 file reader
file_reader是将一个.sst file解析成table的过程 其类关系如图:
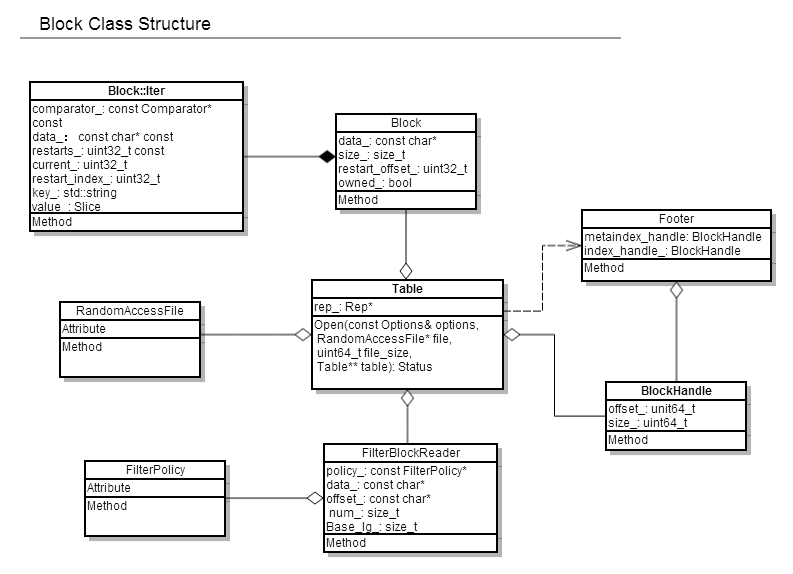
.sst file通过table::open解析, 并使用table::Rep来记录文件信息(levelDB比较喜欢将所有类成员包成rep struct进行访问)
table::Rep结构
3.3.2 file writer
可以看作file reader的逆过程,将若干有序的entries写入并形成.sst文件的过程, 类关系如图:
tablebuilder::rep的结构为:
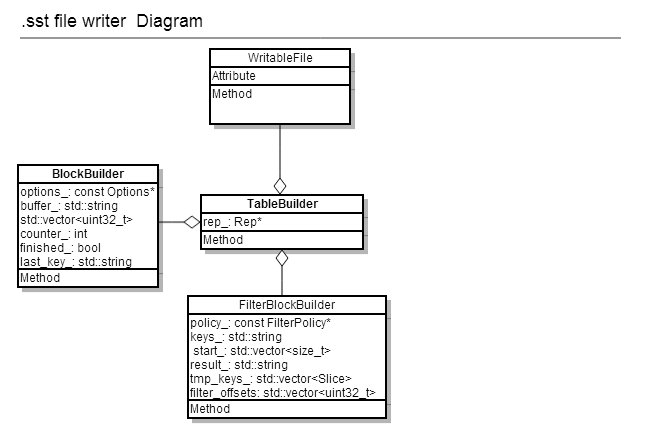
3.3.3 meta block(filter data)
前面已经介绍过,meta block目前只用于存放filter block. 其位于data block之后,为每2KB的数据创建一个filter,用于快速过滤key不在data_block中的请求(提高查找速度),其类图结构为:
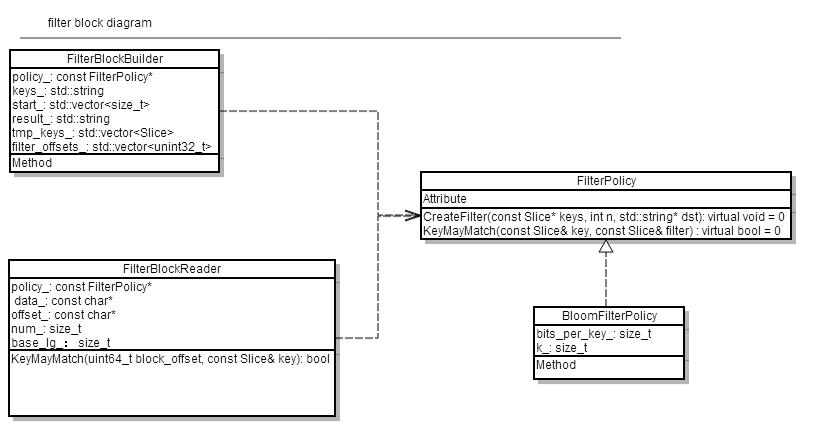
filter clock的结构为:

其中,K(数目和data_block一致)和N的值可能是不等的(其中有些filter是空的,主要是为了快速定位filter)
这是由kFilterBaseLg决定的,filter_offset的index为data_block的offset » kFilterBaseLg, 例如,
当每个data_block为6KB, kFilterBaseLg = 11时,每个filter长度为64时,filter的base为2^11也就是2KB,
那么(0 ~ 6KB-1)的data_block就会进行两次filter,但只有第一个filter是有效的,后面的filter都是空的,其filter_index的结构为:

levelDB中提供的默认filter为bloom_filter(参考及例子:Bloom Filters by Example),也可以使用自定义的filter
3.4 log file
3.4.1 类图结构
levelDB通过log_file进行版本控制,数据恢复和快照(主要利用SequenceNumber),主要通过log::Reader和log::writer进行读写
log writer的结构如图所示:
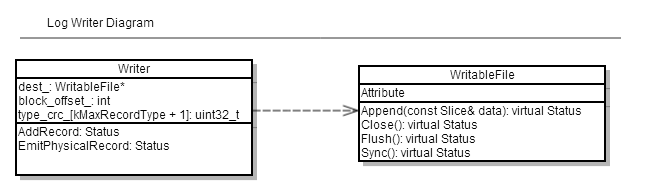
log reader的结构如图所示:
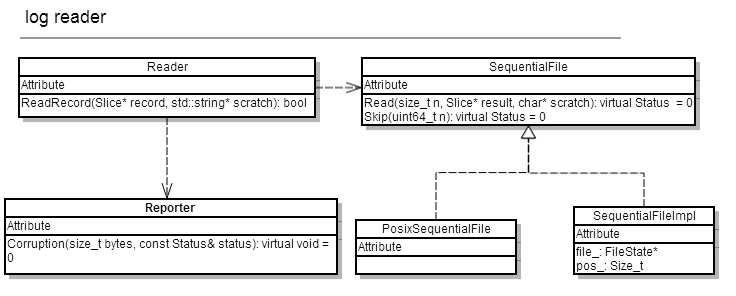
3.4.2 文件结构
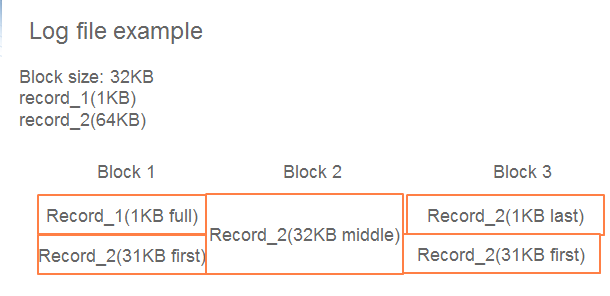
log file由若干大小为32KB的block组成,每个block由若干record组成,每条record的结构为:

checksum为32位的crc校验码,type可能为FULL, FIRST, MIDDLE, LAST中的一种example)
FULL: 表示record完全在这个block中
FIRST: 表示block剩余的offset放不完一整条record,这是record的第一部分
MIDDLE: 表示这部分在record中间且占满这块block, 前面某一块为FIRST,后面某一块为LAST
LAST: 表示这是record的最后一部分,占block的前面部分或是整个block
一个例子:
3.5 manifest file(log file)
每个manifest file会管理这个version所有的信息,其内容结构为:

current file保存了当前manifest file的名字
4 levelDB的key-value读写流程
4.1 写流程
levelDB的写速度相对于读来说速度很快,也比较简单。首先顺序写log文件然后将key-value插入skiplist。dan其流程为:
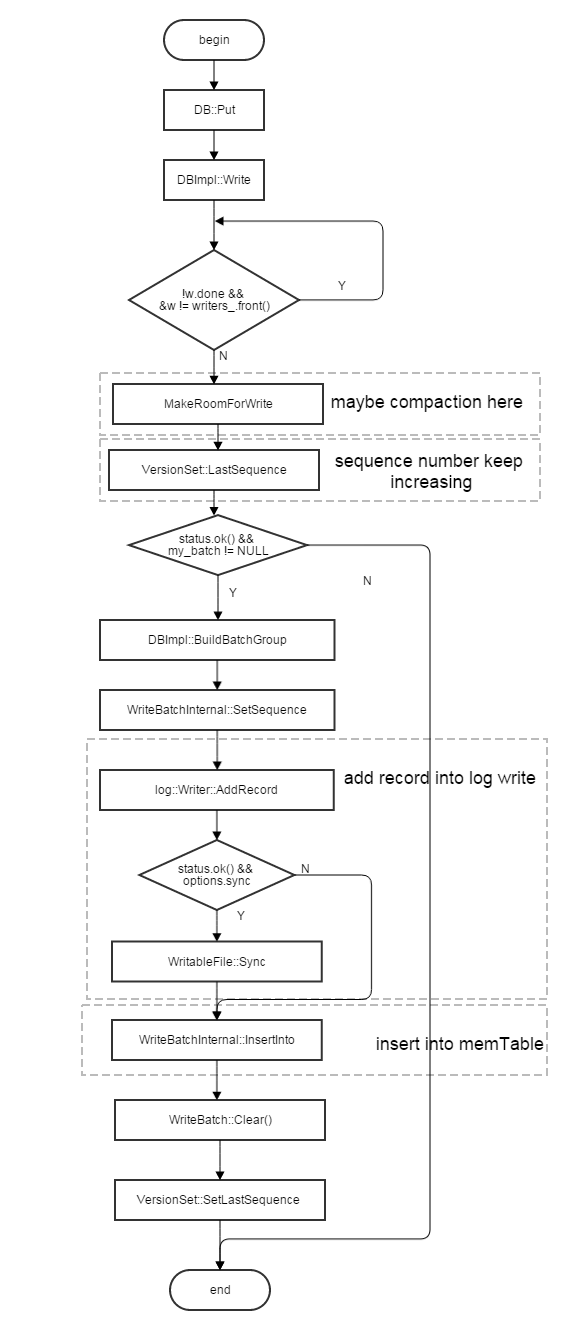
在levelDB中,delete也是作为write_record被写进levelDB的
4.2 读流程
相较于写流程,levelDB的读流程比较复杂,所以读速度远小于写速度,尤其是随机读以及很旧的数据读取,速度会大大降低。数据读速度低的原因在于levelDB中某个key可能存有n条记录,需要读取最新的一条record,因此在查找时需要按照memtable,immutable memtable, level0~levelN的顺序一层一层的查找,如果数据存储在levelN,就要将整个levelDB的所有层都进行查找才能读取数据(会多次磁盘读),才能找到数据。levelDB使用了2种途径来加快查找速率:
- cache, LRU cache缓存最近读过的文件及block,顺序读的速率会高于随机读。
- compaction, 一定条件时触发compaction, 减少冗余数据以及将低层数据向高层移动,后面详细介绍
读流程如图所示:
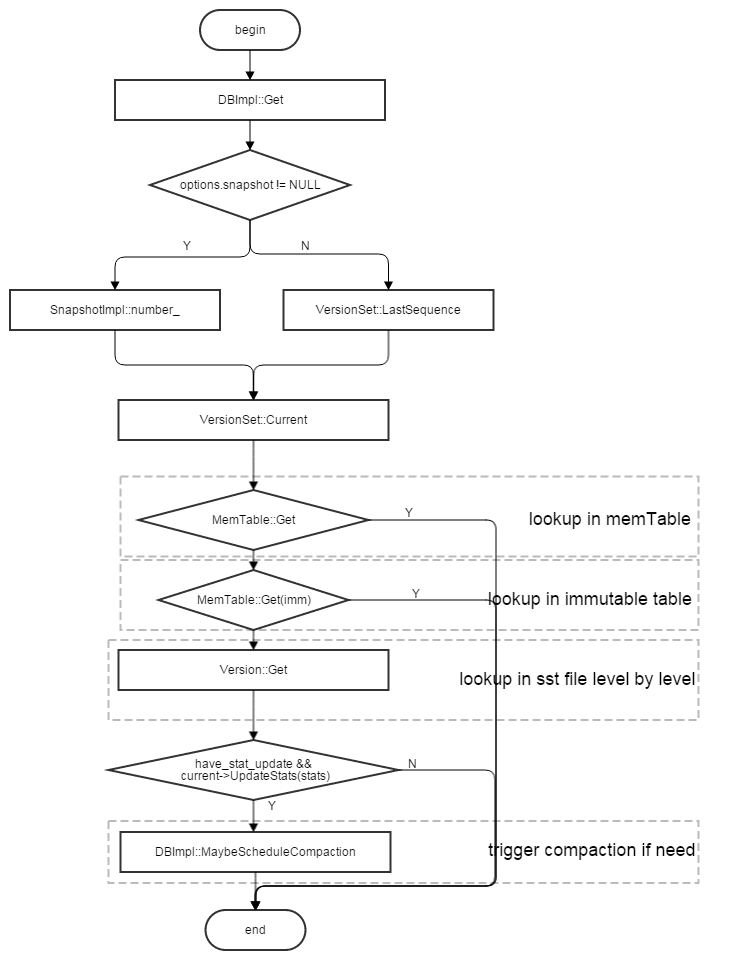
其中:
-
如果在level0~levelN的查找过程中发现需要compaction,就会在查找完成后,通过DBImpl::MaybeScheduleCompaction进行compaction
-
Version::Get会从当前version的文件中,根据level0~levelN的顺序一层一层进行查找,直到找到key, 其中,level0(文件之间非有序)中的所有文件都会被查找,level(1~N)(文件之间有序)只会查找
5 compaction
levelDB的数据主要都是以.sst文件分为不同level存放在磁盘中的,除了level0, level1~N的文件之间都是key有序存放的。level0的每个文件都是来由一个immutable_table生成的,所以文件之间可能会存在key range的重叠,level0的compaction与其它level有点区别,他要将level0中所有含有compaction range的文件与level 1进行compaction. 那么确定哪个level需要compaction:
- 当level0中的文件数目超过一定数目(4个)时,会将level0中所有的data和level1中的data进行merge,生成新的level1文件(每2M data为一个文件)
- 当level1~N中的levelK的data size超过(10^K)MB,就会将levelK中的一个文件和level(K+1)中的所有文件merge生成新的level(K+1)
- 当level的查询次数到达阀值时,该level就要进行compaction
而compaction range则是由上次该level的compaction range的最后一个key的下一条开始的(compaction比较均匀),通过compaction, data逐渐从低层向高层移动,以减少查找及遍历开销
compaction的总流程图为:
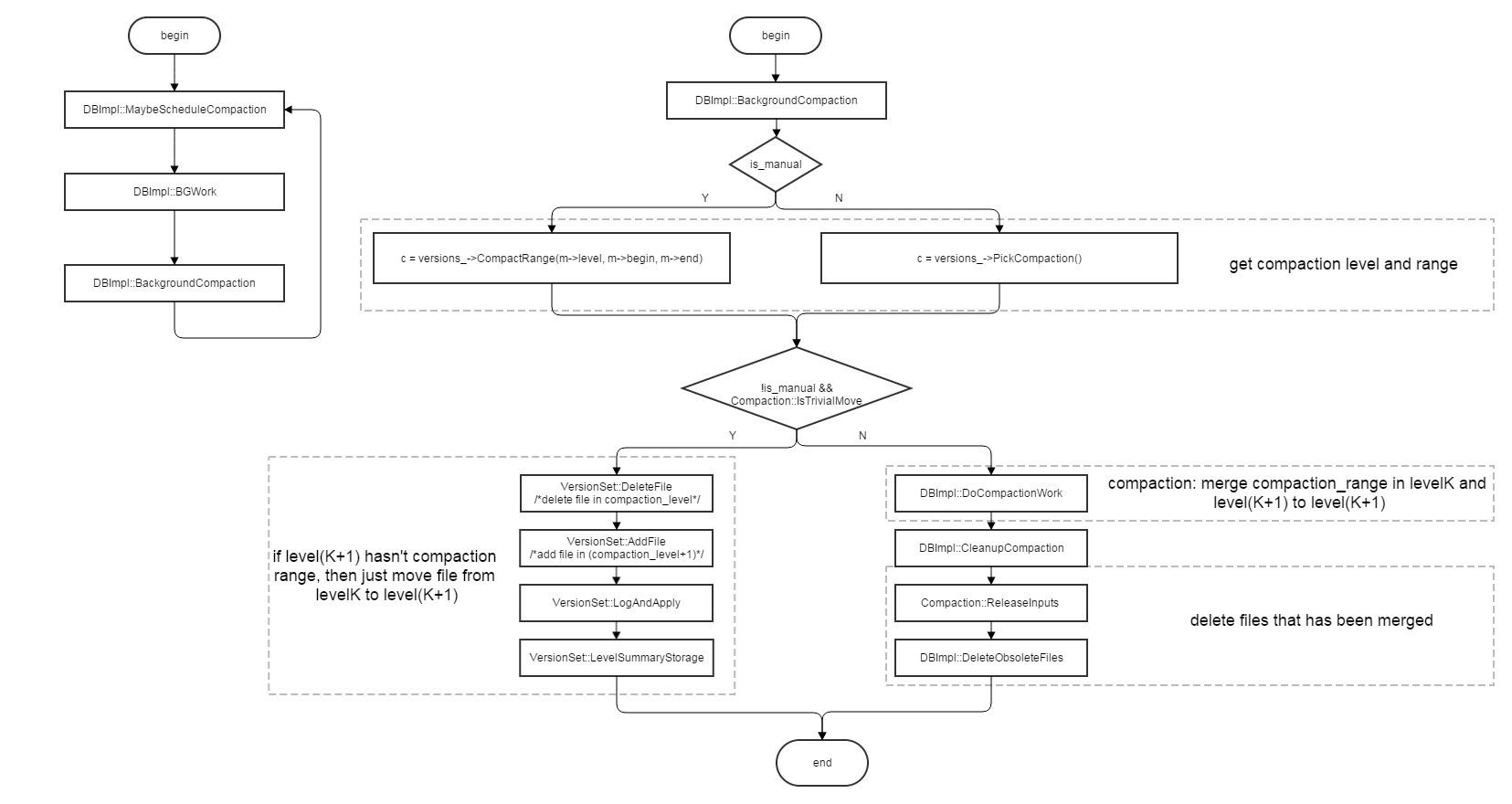
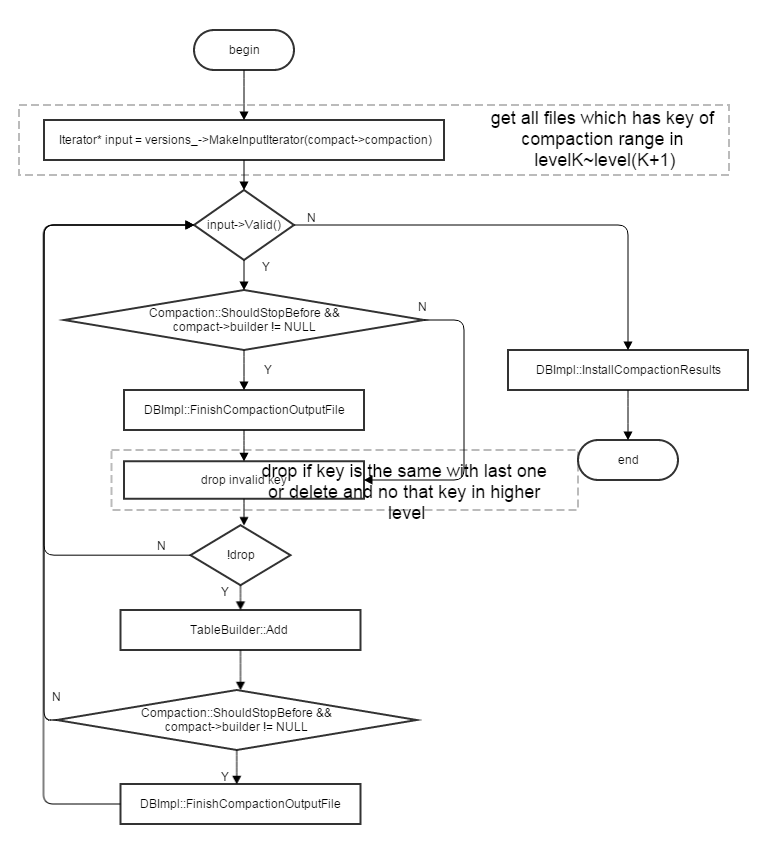
当compaction不仅仅是将levelK的某个文件直接移动到level(K+1)时,DBImpl::DoCompactionWork会将compaction中的input files(包括levelK文件及level(K+1)中与其重复range的文件) merge形成level(K+1)的output files, 其流程图为:
6 Iterator
Iterator是levelDB中所有查找、遍历以及归并的执行者。这些iterator的关系为:
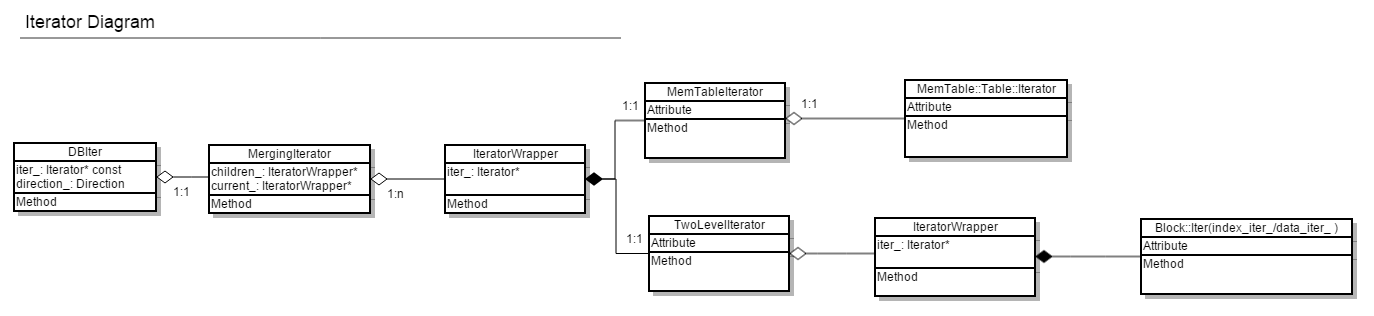
其中:
- TwoLevelIterator是用于遍历每个sst文件iter,其中包含一个index_iter_以及data_iter_, data_iter_初始是空的,在seek到index_iter_时,调用InitDataBlock时才会被初始化。
- MergingIterator则存放了一个iterator list,混合遍历list中的各种结构, compaction中的主要归并功能由其实现,由于key相同时,sequence number会以降序排列,因此key相同时,旧的数据会被drop
- DBIter中含有一个MergingIterator(InternalKey有序),其主要功能也是遍历整个DB data,但是它需要考虑sequence number,进行快照恢复和版本数据管理
例入:MergingIterator的遍历过程
当MergingIterator
example 1:MergingIterator的遍历过程
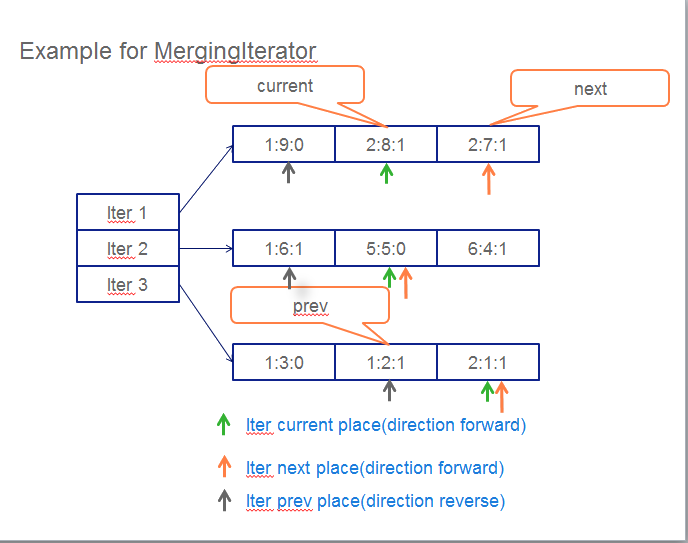
当MergingIterator管理3个iterator时,每个iterator当前指向绿色箭头所指位置, current在2:8:1(user_key:sequenceNumber:valueType)的位置,方向为forward, 怎么找到prev和next呢:
- 找next的过程: 假设当前方向为forward, current位置所在的iter移动到next,然后在3个iter的指向位置(橙色箭头所指位置)找最小值为2:7:1, 方向仍为forward
- 找prev的过程: 假设当前方向为forward, 所有的iter都移动到prev,然后在3个iter的指向位置(灰色箭头所指位置)找最大值为1:2:1, 方向改为reverse
example 2: DBIter的遍历过程
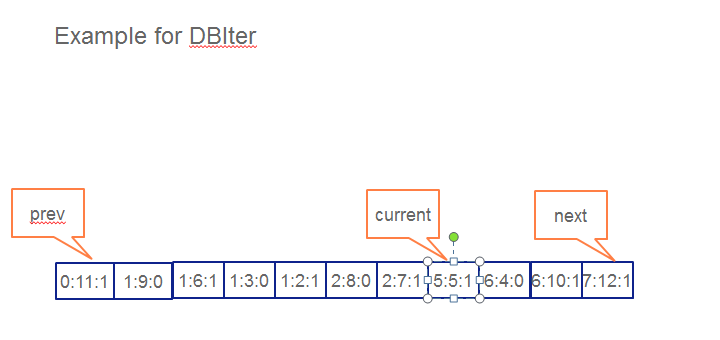
DBIter包含了一个MergingIterator,因此可以看成一个已经有序的遍历,DBIter需要做一些版本相关的处理,假设当前处于current(5:5:0)位置,方向为forward,那么怎么找到它的prev及next呢:
- next: 方向为forward, 首先next到6:4:0, 由于这个数据的type是delete, 跳过所有user_key为6的节点,到7:12:1,该entry的type不是delete,即为next
- prev: 方向为reverse, 首先prev到2:7:1,保存key值2,一直向前找到key值2的开头entry 2:8:0,由于这个数据的type是delete,继续向前, key值为1的最开始节点为delete,也都被跳过,找到0:11:1, 即为prev
睿初科技软件开发技术博客,转载请注明出处
blog comments powered by Disqus
发布日期
标签
最近发表
- volatile与多线程
- TDD practice in UI: Develop and test GUI independently by mockito
- jemalloc源码解析-核心架构
- jemalloc源码解析-内存管理
- boost::bind源码分析
- 小试QtTest
- 一个gtk下的目录权限问题
- Django学习 - Model
- Code snippets from C & C++ Code Capsule
- Using Eclipse Spy in GUI products based on RCP
文章分类
- cpp 3
- wxwidgets 4
- swt/jface 1
- chrome 3
- memory_management 5
- eclipse 1
- 工具 4
- 项目管理 1
- cpplint 1
- 算法 1
- 编程语言 1
- python 5
- compile 1
- c++ 7
- 工具 c++ 1
- 源码分析 c++ 3
- c++ boost 2
- data structure 1
- wxwidgets c++ 1
- template 1
- boost 1
- wxsocket 1
- wxwidget 2
- java 2
- 源码分析 1
- 网路工具 1
- eclipse插件 1
- django 1
- gtk 1
- 测试 1
- 测试 tdd 1
- multithreading 1