Memcached源码解析
发布者:
Renjian Qiu
一 基本介绍及代码结构
memcached是一个非常有名的高性能分布式缓存系统,
采用memcached作为缓存系统能显著提高系统的性能。
想要更好地发挥对memcached的性能,
对其源代码进行分析显得非常必要。 本文基于memcached-1.4.15进行源代码分析,
假设读者对socket, 管道,多线程编程, hash算法等概念有基本的了解。文系列将从以下几个方面展开分析:
- 基本介绍
- 代码结构
- 线程机制
- 内存机制
本文将主要介绍前面两个部分,后面两个部分其他文章会进行介绍。
memcached基本介绍
- 概念与特点
- 使用场景
- 系统架构
- 一致性hash算法
- 基本命令
概念与特点
作为一个缓存系统,memcached的主要任务在于通过在内存中缓存一些常用数据,减少对数据库的存储操作,一方面将数据存储在内存中, 加快数据的存储速度;另一方面减轻数据库的负载,提高数据库的利用率。 如下图所示:
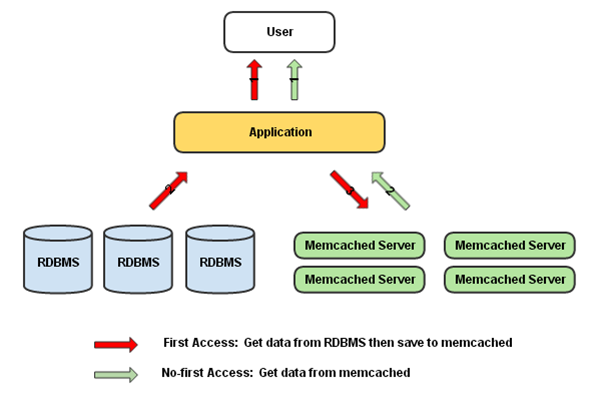
在应用程序首次获取数据时,从数据库中获取数据,并存储memcached服务器中,再次获取数据时,先查找memcached是否存在所需要的数据,
若存在,则从memcached中返回数据,否则,从数据库中获取, 这也是数据库缓存的基本流程。memcahced是一种开源的高性能分布式
内存对象缓存系统,主要通过减轻数据库负载来加速动态网页应用的访问。主要具有以下几个特点:
- 采用协议简单
主要采用TCP连接同server端进行通信,命令基于简单的文本行协议。
- 基于libevent进行事件处理
libevent是一个高效的事件处理框架,采用libevent进行事件处理,既能减少memcached本身的复杂度,
同时能有效结合libevent跨平台高效处理事件响应的特性,保证memcached的事件处理能力。
- 采用内置键值对的内存存储方式
采用用hash表来存储键值对,保证数据的高效存取,将数据存储在内置的内存空间,结合LRU(Least Recent Used)
算法自动删除使用频率最低的缓存,既能减少memcached所占的存储空间,又能保证数据访问的速度。
- 采用独立的分布式服务器
memcached的“分布式”特指客户-服务器之间一对多的分布式映射,服务器之间不存在分布式的概念,
各个memcached服务器之间不会互相通信实现信息共享, 也不会对存储对象进行复制备份保证数据
的安全性(实现备份来保证数据安全性需要额外的开销,cache数据没有必要保证这样的可靠性)。
memcached的使用
从终端输入以下命令
Server: ./memcached -p 11211 -d -u rqiu -m 512 -c 1024 -vv
这里使用的一些基本选项的内容如下
| 选项 | 说明 |
|---|---|
| -p | 使用TCP端口连接,端口号为11211 |
| -u | 用户名 |
| -m | 最大内存值,默认为64M |
| -c | 最大连接数,默认为512 |
| -vv | 用very verbose模式启动,控制台输出调试信息和错误 |
| -d | 采用daemon方式后台启动,这里方面调试,未加-d选项 |
| -h | 帮助信息,显示更多的选项 |
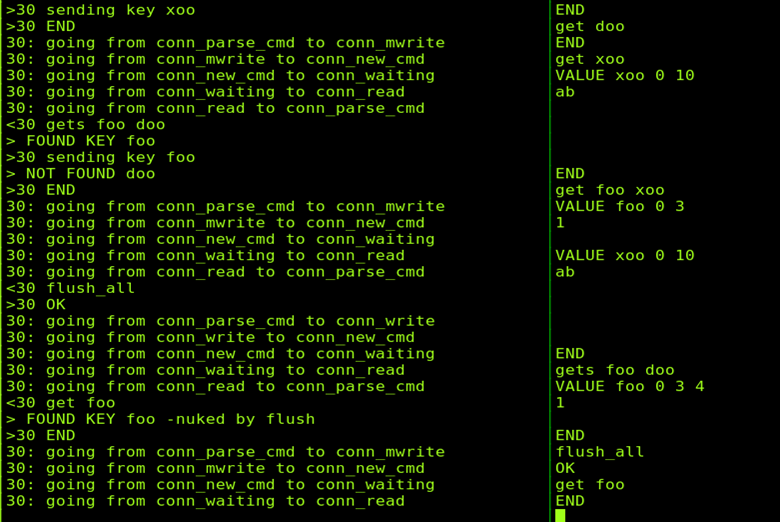
在server端启动memcached服务器后,可以在Client输入一下命令进行连接:
Telnet localhost 11211
然后就可以进行memcached进行set, get等操作了,下图为运行图:
memcached系统架构
如图, memchaced采用的是C-S架构,客户端并非“用户”的客户端, 而是能够处理用户请求并进行分布式处理的“中间服务器”。
客户端和memcached服务器端采用socket进行通信。Memcached服务器的主要工作就是处理客户端的命令请求,采用master-worker模式
的多线程机制, 主线程与工作线程采用管道通信,主线程负责监听事件请求,然后通过管道分发给不同的工作线程, 工作线程根据
主线程提供的相应信息,与socket端建立真正的连接进行数据接收和处理。memcached服务器的线程机制后续会做详细介绍,这里不再赘述。
这里将分布式的客户端和进行实际存储的memcached服务器分离的做法有利于减轻memcached的负担,使其能够专注于实际的数据处理工作,
同时, 也保证了memcached服务器的扩展性,便于memcached服务器的添加和删除,此外,客户端选择分布式的memcached服务器,各服务
器之间独立工作,互不通信,可以显著减少系统的通信开销。
一致性hash算法
从用户发送命令到数据存储到内存中, memcached经历了三个阶段的hash。
- 客户端接收请求调用hash算法选择对应的服务器来进行后续操作,将键值对的存取操作分配到不同的memcahced服务器
- 在memcached服务器中主线程根据简单的hash算法选择特定的工作线程进行任务分发
- 工作线程根据特定的key值采用hash算法进行键值对的存储操作
注意这里,上述三个阶段hash采用了不同的hash算法,阶段2采用的是简单的求余操作完成hash,
阶段3采用的分桶加链表的方法,通过key值定位到
特定的桶中,
然后采用key值比较的方式进行定位,这里不做详细介绍。阶段1需要考虑到memcached服务器增减的情形,简单的求余hash不能满足需求,
采用了一致性hash算法,如下:
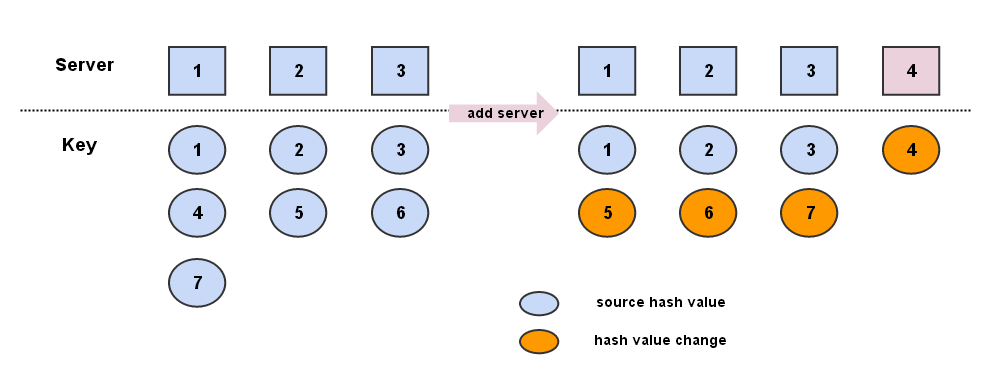
上图为采用求余hash算法得到的不同key对server的映射情况,添加服务器后,7个键值对有4个失效,需要重新hash,采用求余算法虽然能够获得不错的散列性。
但当键值对非常多的时候,增加或删除服务器将会导致大面积的键值对失效,导致缓存更新,代价太大,一致性hash算法能够很好地解决这个问题。
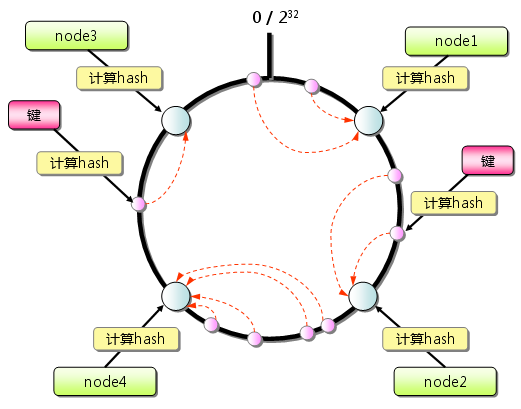
一致性hash算法的思想比较简单,首先建立一个有1-2^23个位置的圆环,把所有server按照一定的hash值映射到圆环上,然后采用特定的算法把键值对映射到圆环上。
沿着键值对在圆环上的位置顺时针找到的第一个server点对应的server就是键值对所需要存放的位置。为了实现服务器之间的负载均衡,同时保证该hash算法具有良好的散列性,可以采用虚拟节点的方法对其进行改进:用一个物理server对应多个虚拟server,虚拟server再按照一定的算法映射圆环上,保证一个键值对存放到个server上的概念大致均衡。那么一致性hash算法怎么解决上面求余hash添加或删除server的问题呢?见下图:
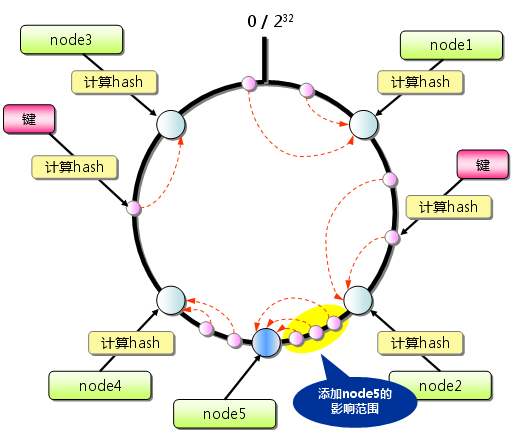
当添加server时,将在圆环上增加改server的映射点,则该变动的影响就局限于添加server的映射点与其逆时针方向的第一个server点之间对应的键值对了。
上图中添加node5后,是原本node5和node2之间原本映射到node4上的键值对映射到node5上了,由此可以最大限度地减少添加server造成的键值对失效数目。
一致性hash算法现在应用场合较多,网上关于其介绍也比较多,这里不再详细介绍,感兴趣可以参考http://thor.cs.ucsb.edu/\~ravenben/papers/coreos/kll+97.pdf。
基本命令
memcached主要分为三种类型的命令:
| 类型 | 概念 | 具体命令 | 格式 |
|---|---|---|---|
| storage commands |
通过key在server端以键值对的 形式存储数据,完整的操作包含 两行输入:命令行和数据行 |
set,add, replace append, prepend, cas |
<command name> <key> <flags> <exptime> <bytes> [noreply]\r\n cas <key> <flags> <exptime> <bytes> <cas unique> [noreply]\r\n |
| Retrieval Commands | 用户端通过一个或多个key从 server端获取key值对应的键值对, 完整操作为输入key,返回数据 |
get, gets | <command name> |
| Other commands | 其他不涉及到数据的输入输出 的命令 |
delete, incr/decr, touch, slabs reassign, slabs automove, stats, flush_all, version, quit |
各命令的基本使用请参考官方网站,这里主要介绍一些命令的注意事项:
- add命令必须在memcached中不存在相应key才能作用
- replace命令要求memcached中必须存在相应key才能作用
- set命令不管key存在与否,强制进行set操作
- cas(check and set)命令的使用涉及到一个版本号的概念,这里为cas unique id,即键值对存储到memcached中时,会有一个特定的cas unique id, 使用cas命令时,要求跟随一个cas id作为参数输入,当输入的cas id与key对应的数据目前的cas id一致,才进行键值对的set操作
- gets命令为根据多个key一次获取多个键值对,用来提高获取数据的效率,但是当这些key映射在不同的server上时,客户端需要同多个server进行通信,gets的意义不大,所以使用gets操作时,用户应该尽量保证多个key映射在同一个server上
- touch命令涉及到一个过期时间(exptime)的概念,即在将数据存储到memcached中时,会设置一个过期时间,当前时间超过过期时间时,数据将自动失效,touch命令即用来更新数据的过期时间。
- flush_all用来清除memcached中所有时间,主要采取将所有数据设置为过期的方式实现
- slabs ressign, slabs automove主要用来在subclass之间转移slab, 后续会做介绍。
代码结构
代码文件:
| hash.h\hash.c | hash算法 |
| assoc.h\assoc.c | Hash表的管理 |
| items.h\items.c | 服务器端item对象管理 |
| slabs.h\slabs.c | 服务器端内存对象管理 |
| memcached.h\memcached.c | 主函数及控制逻辑 |
| thread.c | 线程机制 |
| stats.h\stats.c | 数据统计 |
| util.h\util.c | 工具程序 |
| Protocol.txt | 帮助文档,参数概念 |
全局数据结构
两个比较重要的全局数据结构,setting为系统配置结构, stats的系统状态记录结构,参数详细信息见代码,关键参数已用中文注释。
struct settings {
size_t maxbytes; /* memcached最大容量 初始化64M -m*/
int maxconns; /* 最大连接数 初始化1024 -c */
int port; /* tcp端口 初始化11211 -p */
int udpport;
char *inter;
int verbose;
rel_time_t oldest_live; /* ignore existing items older than this */
int evict_to_free;
char *socketpath; /* path to unix socket if using local socket */
int access; /* access mask (a la chmod) for unix domain socket */...
double factor; /* chunk之间的增长因子,默认值为1.25 -f*/
int chunk_size;
int num_threads; /* memcached中工作线程数目,默认值为4 -t*/
int num_threads_per_udp; /* number of worker threads serving each udp socket */
char prefix_delimiter; /* character that marks a key prefix (for stats) */
int detail_enabled; /* nonzero if we're collecting detailed stats */
int reqs_per_event; /* Maximum number of io to process on each
io-event. */
bool use_cas;
enum protocol binding_protocol;
int backlog;
int item_size_max; /* slab中最大item的大小,初始化1M */
bool sasl; /* SASL on/off */
bool maxconns_fast;
bool slab_reassign; /* 是否允许slab reassign */
int slab_automove; /* 是否允许slab automove */
int hashpower_init; /* 初始化的hash power level */
};
struct stats {
pthread_mutex_t mutex; /* 互斥信号量 */
unsigned int curr_items; /* 现在有效item数*/
unsigned int total_items; /* 总共存储的item数*/
uint64_t curr_bytes; /* 现在有效的字节*/
unsigned int curr_conns; /* 当前客户端连接数*/
unsigned int total_conns; /* 总共连接数*/
uint64_t rejected_conns; /* 拒绝过的连接数*/
unsigned int reserved_fds;
unsigned int conn_structs;
uint64_t get_cmds; /* get命令数目*/
uint64_t set_cmds; /* set命令数目*/
uint64_t touch_cmds; /* touch命令数目*/
uint64_t get_hits; /* get命中数目*/
uint64_t get_misses; /* get丢失数目*/
uint64_t touch_hits; /* touch命中数目*/
uint64_t touch_misses;/* touch丢失数目*/
uint64_t evictions; /*回收item数目*/
uint64_t reclaimed;
time_t started; /* when the process was started */
bool accepting_conns; /* whether we are currently accepting */
uint64_t listen_disabled_num;
unsigned int hash_power_level; /* 初始的hash_power_level, Better hope it's not over 9000 */
uint64_t hash_bytes; /* hash表的size */
bool hash_is_expanding; /* If the hash table is being expanded */
uint64_t expired_unfetched; /* items reclaimed but never touched */
uint64_t evicted_unfetched; /* items evicted but never touched */
bool slab_reassign_running; /* slab reassign in progress */
uint64_t slabs_moved; /* times slabs were moved around */
};
总结:
本文对主要介绍了memcached的基本使用及系统架构,下文memcached源码分析2(线程机制)将主要介绍memcached的线程模型,并对memcached的内存机制进行简要介绍。
参考文档:
二 线程机制
下面为memcached源码分析系列的第二部分,本文主要从以下几个方面分析memcached的线程机制:
- 线程模型
- 主线程
- 工作线程
- 状态机
- 辅助线程
memcahced采用libevent作为处理框架,首先我们对于libevent进行简单介绍。libevent是一个程序库,它将linux的epoll, kqueue, select等事件处理功能封装成统一的接口,
即使服务器连接数的增加,也能发挥O(1)的性能。下面为libevent的建立事件处理的基本API:
main_base = event_init(); /* 创建event_base */
event_set(&ev, listen_fd, EV_READ | EV_PERSIST, cb, *arg);/*设置event */
event_base_set(main_base, &cev); /* 将event与相应的event_base关联*/
event_add(&ev, NULL) /* 将event添加的event_base*/
event_base_loop(main_base, 0); /* 启动事件循环,监听事件响应 */
关于libevent的详细介绍请参考官方文档,这里不再赘述。
线程模型
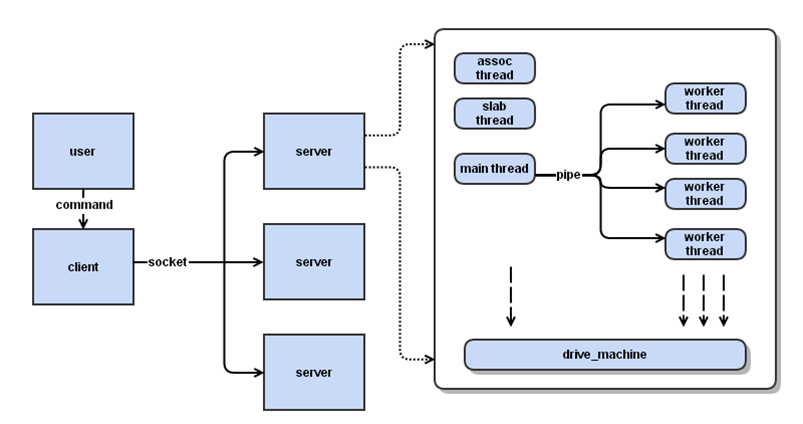
memcached 服务器采用master-worker模式进行工作,这里主要介绍其线程模型,见下图:
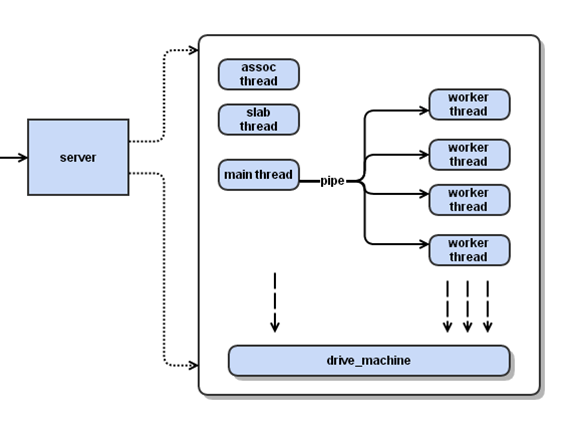
memcached线程模型主要有一个主线程和多个工作线程,另外还包括一些辅助线程,如slab线程,assoc线程,后续会进行介绍。memcached服务器与客户端采用socket通信,
主线程与工作线程采用管道通信。 主线程主要监听socket端的读事件,事件响应时选择合适的工作线程将任务分发出去,相应的工作线程创建与socket端的连接读取数据,
进行实际的数据处理,主线程与工作线程的事件处理流程中将采用状态机实现状态转移。下面介绍线程模型中主要的数据结构:
//工作线程
typedef struct {
//线程ID
pthread_t thread_id; /* unique ID of this thread */
//事件处理框架,每一个线程对应一个event_base
struct event_base *base; /* libevent handle this thread uses */
// 监听管道事件
struct event notify_event; /* listen event for notify pipe */
//管道的读写端口
int notify_receive_fd; /* receiving end of notify pipe */
int notify_send_fd; /* sending end of notify pipe */
struct thread_stats stats; /* Stats generated by this thread */
// 使用的连接队列
struct conn_queue *new_conn_queue; /* queue of new connections to handle */
cache_t *suffix_cache; /* suffix cache */
uint8_t item_lock_type; /* use fine-grained or global item lock */
} LIBEVENT_THREAD;
//主线程
typedef struct {
pthread_t thread_id; /* unique ID of this thread */
struct event_base *base; /* libevent handle this thread uses */
} LIBEVENT_DISPATCHER_THREAD;
此外还有一个表示连接的结构体conn,表示一次连接,它记录本次连接处理请求的状态,该结构体较大,这里就不列出来了。下面我们介绍线程机制的具体流程。
主线程
主线程的初始化工作主要在server_socket()中,它将socket端口监听事件加入libevent的event_base中,负责socket端口读事件的监听,每一个监听端口对应一个socket,
事件响函数为event_handle,通过event_handle进入状态机,从主线程进入状态机的初始状态为conn_listenning状态,各状态的概念将在后面介绍状态机时涉及,主线程初始化代码如下:
// in main(), 在server_sockets中进行主线程的初始化
if (settings.port && server_sockets(settings.port, tcp_transport,
portnumber_file)) {
vperror("failed to listen on TCP port %d", settings.port);
exit(EX_OSERR);
// in server_socket() 创建连接进行事件监听
if (!(listen_conn_add = conn_new(sfd, conn_listening, EV_READ | EV_PERSIST, 1,
transport, main_base))) {
fprintf(stderr, "failed to create listening connectionn");
exit(EXIT_FAILURE);
}
}
//in conn_new 添加libevent事件
event_set(&c->event, sfd, event_flags, event_handler, (void *)c);
event_base_set(base, &c->event);
c->ev_flags = event_flags;
if (event_add(&c->event, 0) == -1)
主线程监听到事件到来时,通过dispatch_new_conn()进行事件分发,其具体实现为:
- 运用简单的hash算法选择一个工作线程
- 创建一个conn_item(该conn_item不是真正的连接,只是包含建立连接所需要的相关信息,如socket文件描述符等。)
-
通过pipe写入一个字符‘c’给工作线程,用于触发工作线程的event_base的事件
/* * Dispatches a new connection to another thread. This is only ever called * from the main thread, either during initialization (for UDP) or because * of an incoming connection. */ void dispatch_conn_new(int sfd, enum conn_states init_state, int event_flags, int read_buffer_size, enum network_transport transport) { CQ_ITEM *item = cqi_new(); char buf[1]; //选择合适的工作线程 int tid = (last_thread + 1) % settings.num_threads; LIBEVENT_THREAD *thread = threads + tid; last_thread = tid; //创建conn_item item->sfd = sfd; item->init_state = init_state; item->event_flags = event_flags; item->read_buffer_size = read_buffer_size; item->transport = transport; cq_push(thread->new_conn_queue, item); MEMCACHED_CONN_DISPATCH(sfd, thread->thread_id); //写入字符‘c’触发工作线程响应 buf[0] = 'c'; if (write(thread->notify_send_fd, buf, 1) != 1) { perror("Writing to thread notify pipe"); } }
工作线程
工作线程进行实际的事件处理工作,其在thread_init中进行初始化,
其初始化流程大致为:
1. 与主线程之间建立管道
2. 初始化连接队列
3. 创建独立的event_base,监听管道的读事件
4. 采用thread_libevent_process作为事件处理函数
代码如下:
//in thread_init(),建立管道
int fds[2];
if (pipe(fds)) {
perror("Can't create notify pipe");
exit(1);
}
threads[i].notify_receive_fd = fds[0];
threads[i].notify_send_fd = fds[1];
setup_thread(&threads[i]);
//in setup_thread,建立event_base,监听事件
me->base = event_init();
...
/* Listen for notifications from other threads */
event_set(&me->notify_event, me->notify_receive_fd,
EV_READ | EV_PERSIST, thread_libevent_process, me);
event_base_set(me->base, &me->notify_event);
if (event_add(&me->notify_event, 0) == -1)
...
工作线程的处理流程如下:
- 从pipe中读取字符触发读事件
- 从连接队列中获取conn_item用于创建真正的连接,从buffer中读取数据
-
工作线程使用上面新创建的连接监听socket事件,进入状态机,进入状态为conn_new_cmd.
//in thread_libevent_process() if (read(fd, buf, 1) != 1) if (settings.verbose > 0) fprintf(stderr, "Can't read from libevent pipe\n"); ... conn *c = conn_new(item->sfd, item->init_state, item->event_flags, item->read_buffer_size, item->transport, me->base); ...
状态机
状态机在memcahced线程模型中至关重要,主线程通过状态机实现对工作线程的分发,工作线程通过状态机事件命令的解析处理以及响应,下面对状态机进行具体介绍:
memcached连接主要包括以下几种状态:
enum conn_states {
conn_listening, /**< 主要为主线程使用 the socket which listens for connections */
conn_new_cmd, /**< 工作线程进入初始状态,开始解析命令Prepare connection for next command */
conn_waiting, /**< waiting for a readable socket */
conn_read, /**< 读取命令行reading in a command line */
conn_parse_cmd, /**< 解析命令try to parse a command from the input buffer */
conn_write, /**< 向客户端写会反馈信息writing out a simple response */
conn_nread, /**< 读取数据行reading in a fixed number of bytes */
conn_swallow, /**< swallowing unnecessary bytes w/o storing */
conn_closing, /**< closing this connection */
conn_mwrite, /**< writing out many items sequentially */
conn_max_state /**< Max state value (used for assertion) */
};
为简单起见,我们在接下来的叙述中将忽略掉一些不重要的状态,如下图:
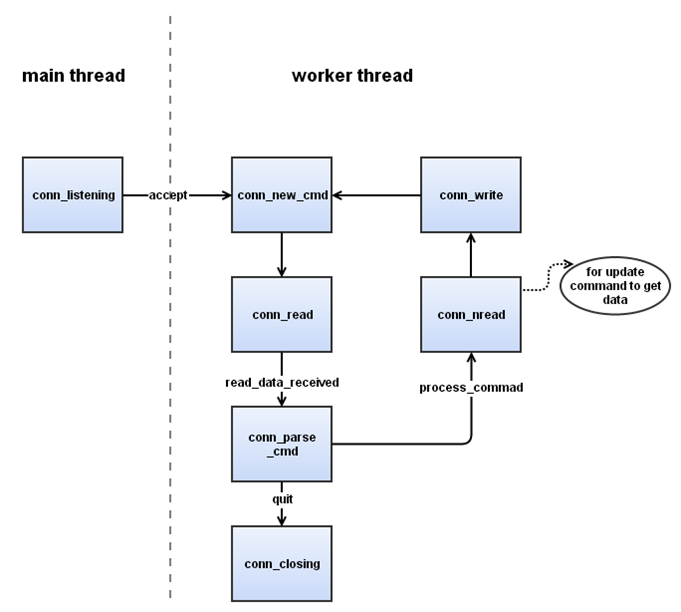
1. 主线程进入conn_listen状态,同过accept函数监听socket事件响应,该状态为主线程独有。
2. 主线程监听到事件响应后,触发合适的工作线程进行事件处理。
3. 工作线程创建连接进入conn_new_cmd状态开始解析命令,由此进入conn_read状态。
4. 工作线程通过conn_read状态读取命令行后,进入conn_parse_cmd状态进行命令解析。
5. 若解析命令后获悉需要获取额外的数据行,则进入conn_nread读取数据行。
6. 处理完之后进入conn_write状态,向客户端写回反馈信息。
7. 以上各状态出现问题时,将直接进入conn_closing等状态,结束当前连接。
一次完整的输入可能包含命令行和数据行,两行数据在不同的连接状态读入并进行解析,下图为解析一次完整输入的详细步骤:
conn_new_cmd为解析输入的初始状态,在conn_write状态向客户端写回反馈后,本次连接会关闭,直到下次事件到来工作线程重新建立连接进入conn_new_cmd,由此形成了一个闭环的状态机。
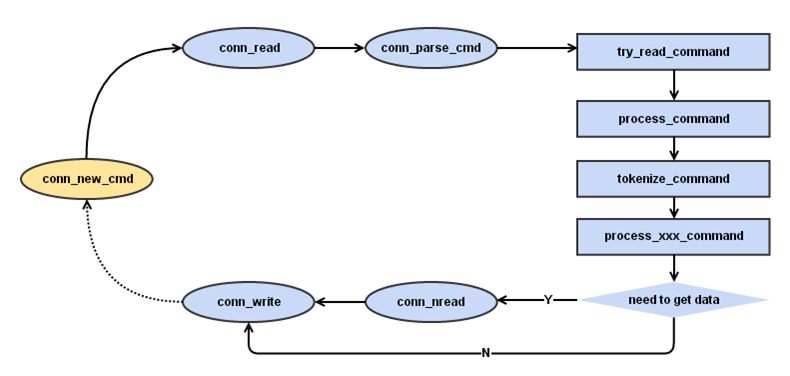
辅助线程
辅助线程主要分为两种,assoc线程和slab线程,两个线程在main函数中进行初始化:
//assoc线程启动
if (start_assoc_maintenance_thread() == -1) {
exit(EXIT_FAILURE);
}
//slab线程启动
if (settings.slab_reassign &&
start_slab_maintenance_thread() == -1) {
exit(EXIT_FAILURE);
}
assoc线程主要负责hash表的管理,负责hash的扩展和维护,这里不做详细介绍。slab线程主要负责实现一个slabautomove的功能,memcahced内存区域分为不同的slabclass,
每个slabclass里面包含相同大小的内存块。slab automove通过在后台运行一个线程, 这个线程会在某些slabclass内存不足时, 在slabclass之间移动内存来保证其正常工作。。slab automove 主要涉及到两个线程slab_maintenance_thread和slab_rebalance_thread, slab_maintenance_thread决定是否需要进行一定, slab_rebalance_thread进行实际的移动工作,两个线程通过一个do_run_slab_rebalance_thread来交互,见下图:
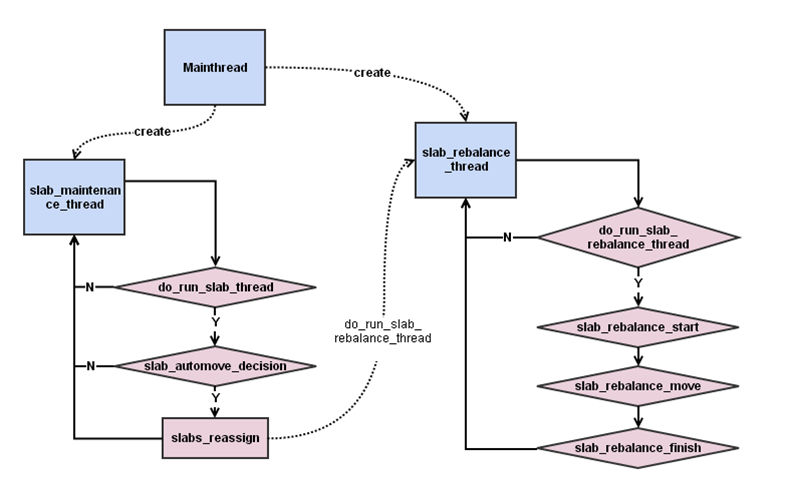
总结:
本文主要介绍memcached的线程机制,memcahced的内存机制和hash表的管理不做详细介绍。
参考文档:
2.http://tech.idv2.com/2008/07/10/memcached-001/
睿初科技软件开发技术博客,转载请注明出处
blog comments powered by Disqus
发布日期
标签
最近发表
- volatile与多线程
- TDD practice in UI: Develop and test GUI independently by mockito
- jemalloc源码解析-核心架构
- jemalloc源码解析-内存管理
- boost::bind源码分析
- 小试QtTest
- 一个gtk下的目录权限问题
- Django学习 - Model
- Code snippets from C & C++ Code Capsule
- Using Eclipse Spy in GUI products based on RCP
文章分类
- cpp 3
- wxwidgets 4
- swt/jface 1
- chrome 3
- memory_management 5
- eclipse 1
- 工具 4
- 项目管理 1
- cpplint 1
- 算法 1
- 编程语言 1
- python 5
- compile 1
- c++ 7
- 工具 c++ 1
- 源码分析 c++ 3
- c++ boost 2
- data structure 1
- wxwidgets c++ 1
- template 1
- boost 1
- wxsocket 1
- wxwidget 2
- java 2
- 源码分析 1
- 网路工具 1
- eclipse插件 1
- django 1
- gtk 1
- 测试 1
- 测试 tdd 1
- multithreading 1