Memcached内存管理
发布者:
Jin-Hua Ouyang
memcached version : 1.4.15
本文期望读者对slab内存分配机制有一定的了解(可以参考这里)
文章结构
memcached是一个“高性能分布式内存缓存系统”,已经被广泛的应用于各个场合。关于它的文档和分析文件也比比皆是,随便google一下就可以得到一大堆的结果。
本文将从按以下结构分析memcached内存池机制。
- 背景知识
先简单介绍几个基本概念。slab 机制, LRU,CAS等。
- SGI次级空间配置出发
本文从SGI次级配置出发,这是一个典型的内存池。它实现简单,而且很多人都对它的结构和代码有所了解(参考侯捷《STL源码剖析》)。作为对比,它能帮助我们理解memcached内存池“为什么”,这个设计的问题。
需要说明的是,本文只是简要介绍它的内存池实现原理。并假定您对SGI内存池有一点的了解。
- memcached内存管理
a) 问题引入。对比SGI内存池,我们会发现一些memcached需要解决的需求。然后带着这些需求的问题来了解memcached的设计和实现。
b) 内存结构图。首先介绍一张memcachedslab机制的结构图。它很好的宏观的描述了memcached的内存结构。
c) 主要介绍slabclass_t 数据结构,及其相关的实现细节。
d) item。item的数据结构和相关实现细节。
e) 回答a) 中提出的问题。memcached是怎样解决这些问题的。
背景知识
-
slab 机制。
它的思想是:针对一些经常分配和释放的对象(通常较小,不大于1M);先分配一个较大的内存单元(一页);然后把它划分成 一个一个较小的单元(80bytes 等);并用一个数据结构来记录小的内存单元的使用情况(空闲,被占用)。释放时,不直接free空间,而是将它的标识位设为空闲。
这样可以避免不断的malloc free系统内存而造成很多内存碎片。
可参考:http://en.wikipedia.org/wiki/Slab_allocation -
LRU
Least Recently Used 近期最少使用算法。
这是一种页面置换算法,它的思想是在每次调换时,找到最近最少使用的那个页面调出内存。 可参考http://en.wikipedia.org/wiki/Cache_algorithms#Least_Recently_Used -
slab, chunk, item
memcached的内存单元,它的对应关系是: 一个slabclass 包含多个slab; 一个slab包含多个大小相等的chunk;真正存放memcached数据的最小单元item就放在chunk中。详见下图2。 -
CAS
Check and set.在Memcached中,每个item关联有一个64-bit长度的long型惟一数值,表示该item对应value的版本号。当多个线程同时修改一个item,会利用这个版本号进行check。
SGI 次级空间配置
让我们先从一个相对简单的例子,SGI 次级空间配置出发。
关于这一点,可参考侯捷《STL源码剖析》。翻看了一下gcc3.4.6源码,代码内容和结构跟书中介绍的在形式上有一点小小的不同。(相关代码可参考include/ext/pool_allocator.h,src/allocator.cc)
问题
SGI给出了memory
pool一个简单的经典实现。对于128bytes一下的内存分配,会采用该种策略。
要实现一个memory pool,要解决的几个最基本的问题是:
- 如何存?
- 如何取?
- 存在哪?(用什么样的数据结构)
- 何时释放内存?何时”换页“?
结构图
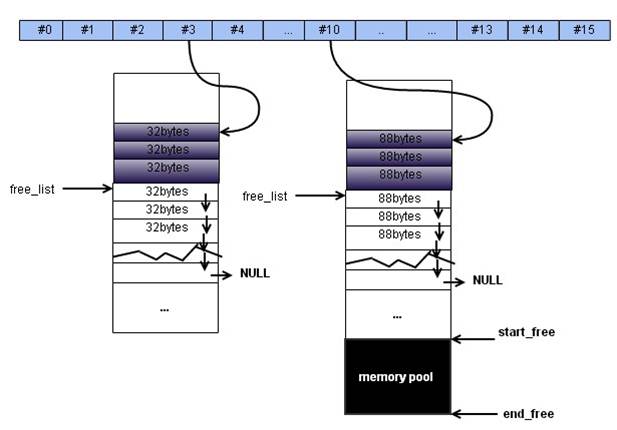
图1. SGI内存池结构图
SGI的内存池由16个桶组成,每个桶包含多个大小为 8~128 bytes的存储单元。(上图蓝色部分)
如上图,每个桶有大小相同的chunk组成(chunk是存储数据的单元)。包括已占用的,图中用深色标识;和未使用的,它是一个chunk链表,并由free_list索引。 然后,它还有一个start_free到end_free的内存池。
答案
那么我们来回答上面四个问题:
- 如何存?
每达到一个数据,会根据数据的大小,分到对应的内存区间;然后在区间中,尝试分配寻找free list,找到后就将对应的内存放入。找不到则从start_free 到end_free尝试重新填充free list。如果start_free -> end_free 没有足够的内存空间,则会尝试从内存malloc。
- 如何取?
对于这个问题,似乎不需要回答。因为”用户“持有存储单元的指针。 -
存在哪? 真正存储数据的地方在这里:
union __Obj { union __Obj* free_list_link; char client_data[]; };
采用union是因为它空闲时就成为指针,有数据时则变成容器。
- 何时释放?何时“换页”?
当该块内存空间不再需要使用时,比如说vector<int>容器退出作用域而被释放。释放的时候内存单元就变成一个__Obj指针,被挂到free_list上。
何时”换页“,SGI次级配置似乎没有考虑换入换出和数据过期的问题。因为它的接口不是对外开放的。
一个值得注意的地方是:每个内存区间(8~128bytes)所用来存放数据的__Obj并不是内存连续的,它们甚至都不需要在同一个page上。
优缺点:
几乎没有额外的内部碎片。实现简单,用来存储内存单元的__Obj把空间节省利用到极致。而由于它本来就不是一个被design成外部使用的代码,缺点也是非常明显。
- 它的使用方式不灵活
- 缺乏一种swap-out机制
- 不是线程安全的
…
memcached 内存管理
本文是基于memcached1.4.15,因此跟网上许多文章有所不同。
一个典型是在老版本的memcached,slabclass_t有
void *end_page_ptr;
unsigned int end_page_free;
memcached1.4.15版之前已经去掉了这两个成员。
问题
SGI次级空间配置的缺点,恰恰是memcached需要解决的问题。 那么,memcached需要解决的需求是:
- 多线程支持。
- “换页”机制。如何把不使用的空间还给内存池。
- 怎么样快速访问。(SGI次级空间配置不存在这个问题,是因为他把__Obj所在地址的指针给了用户)
让我们带着这几个需求来看memcached的内存管理机制吧。
memcached内存结构图
下图是引自互联网的一个结构图,它较好的说明了memcached的内存结构。
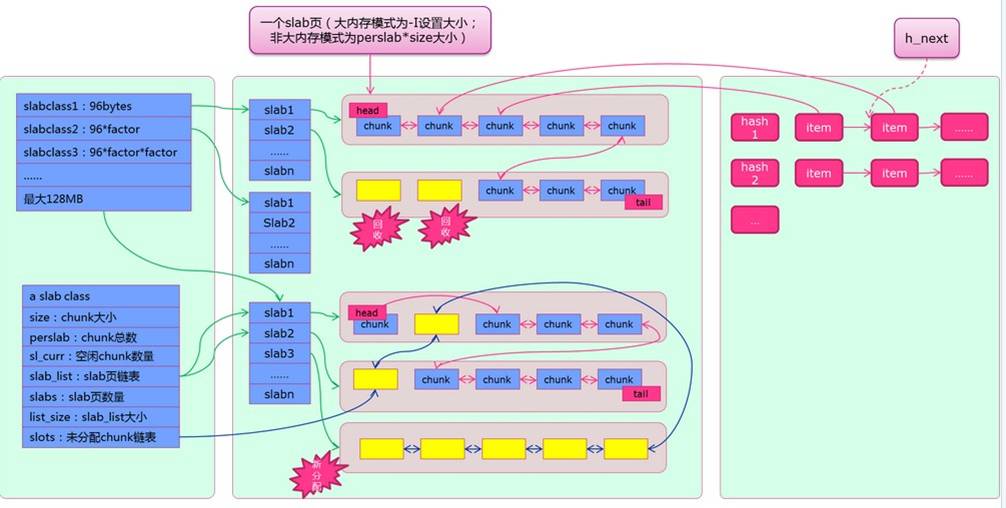 图2.memcached内存池结构图
图2.memcached内存池结构图
上图摘自(memcached-1.4.15内存结构及启动参数 )可以看到,这张内存图,基本上是图1(SGI次级空间配置内存池结构)的升级版。
它泾渭分明的分成了三个部分:
- 最左边的部分是slabclass,及其各种成员的说明
- 中间的部分由slabs, chunk组成
- 最后边的部分是hash结构示例
可以看到,每个slabclass 有一系列的slab,他们分别指向大小相同的chunk对象; chunk中蓝色的部分标识表示已使用,黄色的表示尚未使用;
head,tail的数据结构用来保存所有slab已使用chunk的头尾指针;而图中黄色chunk则由slabclass中的slots指针串联起来。 最后红色item是真正存放数据的最小单元,它们被放置在大小合适的chunk中;
而在hash表的同一个桶中,它们则被h_next的指针串联起来,可以看出memcached是使用开链法来解决冲突的。
本来接下来的部分将详细介绍memcached内存池核心数据结构slabclass_t, item及其接口和操作流程。
slabclass
数据结构
typedef struct{
unsigned int size; /*sizes of items*/
unsigned int perslab; /*how many items per slab*/
void *slots; /* list of item ptrs */
unsigned int sl_curr; /*total free items in list*/
unsigned int slabs; /*how many slabs were allocated for this class*/
void **slab_list; /*array of slab pointers*/
unsigned int list_size; /*size of prev array*/
unsigned int killing; /*index+1 of dying slab, or zero if none*/
size_t requested; /*the number of requested bytes*/
} slabclass_t;
注释已经非常清楚,唯一可能会让你感到疑惑的是killing 这个变量。这个变量只在slabs rebalance 过程中会被使用到。当killing被赋以非0值时,它表示当前slabclass中 killing+1 所在slab正在被rebalance。
然后,它定义了
static slabclass_t slabclass[MAX_NUMBER_OF_SLAB_CLASSES];
其中
MAX_NUMBER_OF_SLAB_CLASSES = POWER_LARGEST + 1 ;
define POWER_LARGEST 200
可以看到,slabclass最多有200个。这样就维护了所有的slabclass。
下面三个变量则描述了当前内存的使用情况:
static void *mem_base = NULL;
static void *mem_current = NULL;
static size_t mem_avail = 0;
mem_base唯一的一次赋值操作在slabs_init中,可见它是用来标识是否prealloc并且成功。
mem_current则用来标识在alloc出来的内存中,当前尚未分配给slabclass的;
响应的,mem_avail则记录mem_base - mem_current 的长度。
接口
接下来,我们关心的问题是:slabs是怎样初始化,分配内存,以及回收空间的。
它相关的代码主要在 slabs.h / slabs.cpp 中。
本节将依次介绍slabs_init, slabs_alloc, slabs_free实现细节。
slabs_init
slabs_init在memcached启动函数–main函数中会被调用到。顾名思义,它最要起到初始化内存池的工作。
- 首先,它要初始化slabclass_t这个结构体相关的数据。
- 其次,至于需不需要调用malloc给内存池分配内存,并将内存组织成图2所描绘的形式;还是“用多少配置多少”。
memcached将这个决定权交给了用户。用户可以通过”-L”参数指定。
slabs_init的接口如下:
void slabs_init(const size_t limit, const double factor, const bool prealloc)
其中各参数的含义分别是:
- limit 能够使用的最大内存大小,settings.maxbytes, 默认是64M
- factor chunk增长因子, size * factor ^ n, 默认是1.25;
- prealloc, 是否在init的时候预先分配内存,并用chunk填充.
具体说来,slabs_init是怎样初始化的呢?
- memcached对不同的slabclass
采用的是均分策略。即每个slabclass所占有的空间之和是相等的。
它的值为settings.item_size_max,它的默认大小是1M。
这就要求slabclass_t 中 size * perslab 值恒定。 - 第一个slabclass的chunk大小为settings.chunk_size + sizeof(item).
可以计算出在32位系统下item结构体的大小为32,chunk_size默认值为48(可通过-n修改)
第二个slabclass chunk大小为 第一个的size * factor
以下类推 - 对于最后一个slabclass,memcached做了点小小的特殊处理。将它的size设为settings.item_size_max。
perslab设为1.
另一方面,前面提到,如果指定prealloc,memcached会malloc一个尽量大的内存,然后把它组织成图2所示的内存结构。
- malloca出来的内存大小由参数limit指定
- 第二步调用slabs_preallocate, slabs_preallocate的作用是对每个slabclass 调用do_slabs_newslab进而把perealloc出来的大块内存分割到一个一个的chunk中。在这一步中将完成对slabclass_t中除了size, perslab, killing其他变量的初始化。
必须注意到的一个概念是:这个时候对每个slabclass只会初始化一个slab,这个slab的大小是settings.size_max / size.
让我们回顾一下这整个过程,大致如图:
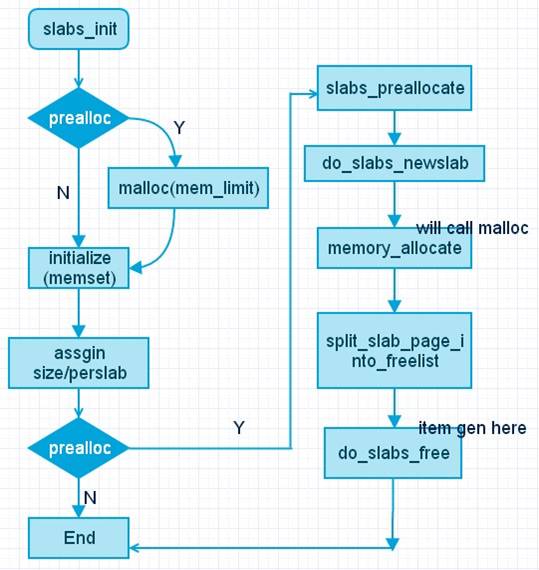
图3. slab_init 调用流程
其中split_slab_page_into_freelist是通过调用do_slabs_free真正将内存块转成item,并链接到slabclass中free list链表slabs上。见下:
static void split_slab_page_into_freelist(char *ptr, const unsigned int id) {
slabclass_t *p = &slabclass[id];
int x;
for (x = 0; x < p->perslab; x++) {
do_slabs_free(ptr, 0, id); //这就是对slabclass中一个slab的处理了。
ptr += p->size;
}
}
do_slabs_free的代码容后介绍。不过我们可以大致猜想它的作用。
如果指定了prealloc参数,经过slab_init后的内存结构图是:

图4. slab_init (prealloc) 之后的memcached内存结构
上图中假定,初始化大小为sizeof(item) + settings.chunk_size = 80.
可以看到,slabs_init之后,memcached为每个slabclass都初始化了一个slab,
其大小为size * perslab (小于1M)
alloc
接下来就是alloc 的过程了,alloc的过程相对比slab_init简单。
static void *do_slabs_alloc(const size_t size, unsigned int id)
注意它的返回值,它的返回值是一个void*。如果这个值不为空,它是由一个item指针强转而来的。
所以它是从slab中拿到合适的item,而不是分配出一个新的slab。
回忆一下前面SGI alloc(如何存)的过程,我们可以猜测slabs_alloc应该是一个类似的过程,即:
1) 首先尝试从free list中取,成功则返回。失败就转到2)
2) 如果free list为空,则new一个slab(注意到newslab会初始化slots)。转到3)
3) 然后从new出来的slab的free list,也就是slots上取一个item.
事实上,memcached也正是这么做的:
static void *do_slabs_alloc(const size_t size, unsigned int id){
...
if (! (p->sl_curr != 0 || do_slabs_newslab(id) != 0)) {
ret = NULL;
}
else if (p->sl_curr != 0) { // 这时可用的free list 可能是原本是存在的,也可能是前面do_slabs_newslab产生的
// 将它挂到 free list 也就是slots上并取一个
it = (item *)p->slots;
p->slots = it->next;
if (it->next) it->next->prev = 0;
p->sl_curr--;
ret = (void *)it;
}
...
}
slabs_free
在第一步slabs_init中最后出现过do_slabs_free的代码。因为是内存池,slabs_free不可能真正的free掉内存。
它的作用是将item对象挂接到slots上。这点跟SGI次级配置毫无区别。
代码也就是双向链表的操作,比较简单:
static void do_slabs_free(void *ptr, const size_t size, unsigned int id) {
...
// 关键代码在这一块
it = (item *)ptr;
it->it_flags |= ITEM_SLABBED;
it->prev = 0;
// 把它插入到slots最前面.
it->next = p->slots;
if (it->next) it->next->prev = it;
p->slots = it;
...
}
当然,slabs还剩下部分代码没有涉及,它是跟slabs automove 这个command相关。本文不会介绍这部分代码,感兴趣的可以参考源代码。
接下来主要分析它的item 结构,接口;以及详细解答本节开头提出的三个问题。
item
这部分将介绍核心数据结构item和它的几个主要操作:
alloc, get, store, link/unlink。
数据结构
item 是真正用来保存数据的,相当于SGI的union __Obj成员,不过它的实现和功能却要复杂的多,使用也要更加灵活。
它的数据结构如下:
typedef struct _stritem {
struct _stritem *next;
struct _stritem *prev;
struct _stritem *h_next; /* hash chain next */
rel_time_t time; /* least recent access */
rel_time_t exptime; /* expire time */
int nbytes; /* size of data */
unsigned short refcount; /* 引用计数 */
uint8_t nsuffix; /* length of flags-and-length string */
uint8_t it_flags; /* ITEM_* above */
uint8_t slabs_clsid;/* which slab class we're in */
uint8_t nkey; /* key length, w/terminating null and padding */
/* this odd type prevents type-punning issues when we do
* the little shuffle to save space when not using CAS. */
union {
uint64_t cas;
char end;
} data[];
/* if it_flags & ITEM_CAS we have 8 bytes CAS */
/* then null-terminated key */
/* then " flags length\r\n" (no terminating null) */
/* then data with terminating \r\n (no terminating null; it's binary!) */
} item;
各成员的含义,注释已经非常清楚。
需要稍微注意的是这里采用了空数组来存储真正的数据,如果对它的实现有疑问的话可以参考这里.
另外一点是,这里采用数组来保存数据(SGI内存池也一样)而不是指针,这很自然,因为真正存放到memcached中数据的长度是
item + data;如果采用指针,则没有办法把它们保存到同一个chunk中。
那么it_flag 包括哪些flag 呢?记录在这里:
#define ITEM_LINKED 1 // 该item已被使用
#define ITEM_CAS 2 // 它使用CAS
#define ITEM_SLABBED 4 // 该item未使用,挂在slots上
#define ITEM_FETCHED 8 // 该状态表示被get 出去了,它唯一一次赋值在do_item_get中
在前面slabs内存结构图中,出现的tails和heads则是这样定义的:
static item *heads[LARGEST_ID];
static item *tails[LARGEST_ID];
他们分别保存了slabclass中每个slab的头和尾.
接口
那么,item是如何工作的呢?它是怎样给存放数据,释放数据(回收)?它的每一个个数据成员又是如何被使用的呢?
先来看item_alloc的过程
do_item_alloc
当用户在memcached客户端输入: set(add …) key 0 0 1 ,它会调用到do_item_alloc 。
看到这里,我们可能会很自然的想起do_slabs_alloc的代码。那一部分代码好像已经完整处理了如果从内存池取一个item的过程。
那么,为什么还需要do_item_alloc呢?
聪明的您可能会马上想起在介绍SGI次级空间配置时说到它的缺陷:
它并没有考虑“换出”的问题。而这正是memcached需要解决的。
memcached维护的headsid到tailsid这个按访问时间(time)降序排列的双向链表,正是用来实现“页面置换算法”LRU的关键数据。
那么,何时执行LRU算法呢?do_item_alloc执行了LRU算法(另一个在do_get_item)。
事实上,do_item_alloc的流程如下:
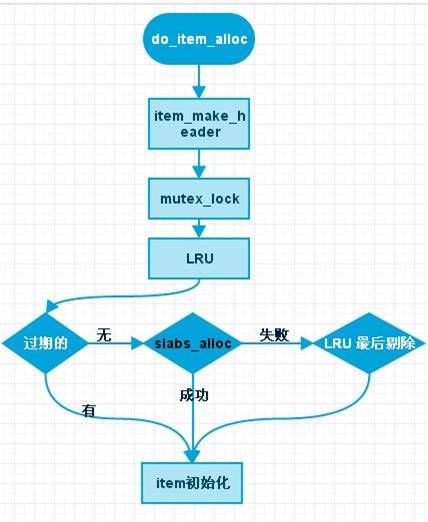
图5. do_item_alloc流程
- 可以看到,它首先对当前的队列执行LRU算法。LRU算法的细节在后面介绍。
- 如果没有过期的数据,就尝试slabs_alloc。可见slabs_alloc并不是它的第一选择,第一选择是执行LRU找到过期的item并加以利用。
-
如果slabs_alloc失败了?那么还有下一步,它会尝试从当前队列里看能否强行踢掉一个。它的规则是:
item *do_item_alloc(char *key, const size_t nkey, const int flags, const rel_time_t exptime, const int nbytes, const uint32_t cur_hv) { ... else if ((it = slabs_alloc(ntotal, id)) == NULL){ ... if (settings.evict_to_free == 0) { itemstats[id].outofmemory++; } else { ... it = search; slabs_adjust_mem_requested(it->slabs_clsid, ITEM_ntotal(it), ntotal); do_item_unlink_nolock(it, hv); ... }
可以看到,如果slabs_alloc的返回值为NULL,表示slabs_alloc失败。
此时,如果settings.evict_to_free被设置(当内存存满时,是否淘汰老数据。默认是1,可以通过-M设置),此时会强行踢掉老数据。
如何能保证踢掉的是老数据而不是新数据呢?之前提到过,LRU队列是时间降序排列的,do_item_alloc执行LRU和强行踢掉的item都在LRU队列尾部。
search = tails[id];
拿到item之后,按照我们“预想”的逻辑,它应该链到LRU队列并插入hash表中。
然而事实上, do_item_alloc并没有这么做!为什么?
从do_item_alloc的参数可以看到,它虽然有nbytes,但却并没有真正的数据。就是说这个item还不是一个有效的item。
当用户输入
> set/add/xxx <key> <flag> <exptime> <nbytes>
> value
其实是两个stat,do_item_alloc只是处理了前一部分的状态(set xxx <key><flag> ...)
第二个状态,也就是真正存值的环节会在后面的问题回答中阐述。
get item
那么,接下来的问题是:用户是如何取到存储的数据的呢?
也就是说当用户在客户端输入:
get key
memcached是如何查找到到对应的内存数据的呢?其中与item祥光的代码在do_item_get。
同样的,我们不妨猜测memcached会如何做:
在前面图2,图3以及item数据结构中都暴露这一实现细节:memcached是用hash表来快速定位item。
因此,它应该是利用用户输入的key,找到合适的value;然后将它返回给用户。
是的,查找到与key相对应的value确实就这么简单。memcached就是这么做的。这部分代码在assoc.c的函数assoc_find中,将在后面介绍。
不过,前文已经提到,在do_get_item中,memcached还将执行LRU算法剔除item。
这样问题就出来了,如果key所对应的value,按照LRU算法应该被回收。那么应该怎么做?
memcached的回答是:把它flush掉。并在客户端给出响应:
-nuked by flush 或者 -nuked by expire
被flush掉和expire有什么区别吗?当然有。从字面上的意思就很容易理解:一个是被某种命令flush掉;一个是过期了。
关于LRU算法和flush命令,在后面都有详细的介绍。
除此之外,memcached在do_get_item的函数中还做了一点小小的特殊处理,如下:
item *do_item_get(const char *key, const size_t nkey, const uint32_t hv) {
...
item *it = assoc_find(key, nkey, hv);
if (it != NULL) {
/* 这部分代码是验证当前所取到的item,
* 是不是rebalance的操作对象, start < it < end;
* 如果是的话,需要把它unlink 并调用remove 减少引用计数;
* 因为rebalance 会对其中的item存储位置进行调整
*/
refcount_incr(&it->refcount);
if (slab_rebalance_signal &&
((void *)it >= slab_rebal.slab_start && (void *)it < slab_rebal.slab_end)) {
do_item_unlink_nolock(it, hv);
do_item_remove(it);
it = NULL;
}
}
...
}
至此, LRU算法真正执行的地方有两个:
- do_item_alloc , 用户存储、更新等操作时;
- do_item_get, 用户查询时。
link, unlink
上面的代码(do_item_alloc, do_item_get)中出现了unlink,
remove的操作。他们的具体作用是什么呢?
在item的数据结构中,维护了三个指针:
struct _stritem *next;
struct _stritem *prev;
struct _stritem *h_next;
前面两个指针维护了一个按访问时间(time)降序排列的用于LRU算法的链表。他们的头尾分别由tailsid和headsid索引着。
另外一个h_next是维护着hash桶中的链表指针。
很自然的,对item的操作都要涉及到这两个队列。link,
unlink主要就是处理这两个操作的。
先看link的代码
int do_item_link(item *it, const uint32_t hv) {
...
// 插入到hash队列中
assoc_insert(it, hv);
// 调用item_link_q 将其加到LRU队列上
item_link_q(it);
// 增加引用计数
refcount_incr(&it->refcount);
...
}
可以看到do_item_link分别调用item_link_q和assoc_insert来将item插入到LRU链表和hash链表中。
item_link_q就是插入到LRU队列了,那么插入到哪个位置呢?
如前文所述,LRU队列是一个时间降序排列的队列;那么新加入的item自然就应该插入到链表头上。
// item_link_q 就是一个链表操作了
static void item_link_q(item *it) { /* item is the new head */
...
// 把它插入链表 成为新的头节点,这样就保证了LRU队列的时间降序
it->prev = 0;
it->next = *head;
if (it->next) it->next->prev = it;
*head = it;
if (*tail == 0) *tail = it;
...
}
那么assoc_insert就是放到hash表中了。同样因为hash表是用开链法解决冲突,新加入的链表也是插在链表的头结点上。
代码也很简单,就是一个链表操作。唯一需要考虑的问题是hash表是否正在扩张。而这不是本文的重点。
unlink 的操作是上述操作的逆操作,相应的,它会调用item_unlink_q和assoc_delete来达到目的。
值得注意的时,在link的时候我们做了refcount_incr的操作,这里需要做refcount_decr;很自然的就需要考虑refcount是否为0,决定是否真正的回收资源。
因此在do_item_unlink 调用的不是refcount_decr而是do_item_remove
void do_item_remove(item *it) {
...
if (refcount_decr(&it->refcount) == 0) {
item_free(it);
}
}
跟前面一样,既然assoc_free已经做了把它放到free list(slots)上的工作。这里在item_free中我们只需要调用它就可以了。
void item_free(item *it) {
...
slabs_free(it, ntotal, clsid);
}
所以,经过do_item_unlink后,slab会变成如下图所示:
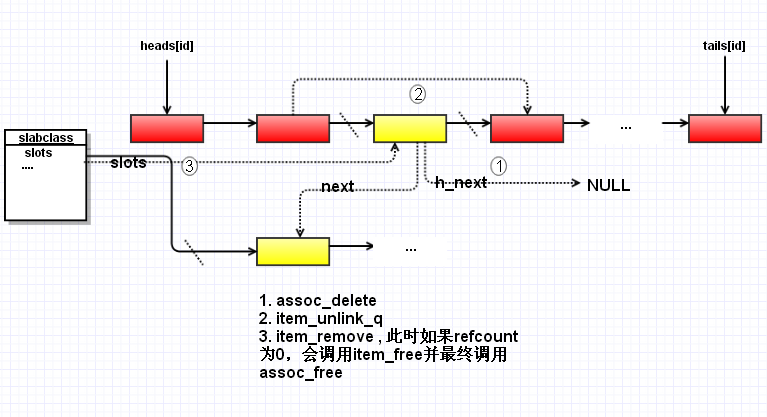 图3.
do_item_unlink 工作流程
图3.
do_item_unlink 工作流程
store_item
要想说清楚这个问题,先要简要介绍一下。memcached存储的工作流程。
当用户在客户端输入:
set key 0 0 1 c
memcached是如何处理这个输入的呢?
如果你启动客户端的时候加入 “-vvv”
参数,这时,可以看到memcached服务端会输入日志:
30: going from conn_read to conn_parse_cmd
30: Client using the ascii protocol
<30 set key 0 0 1
30: going from conn_parse_cmd to conn_nread
> NOT FOUND key
>30 STORED
从屏幕的输入可以明显看到:对于set
命令,memcached内部发生了两次状态转换,也就是两个动作。
具体来说,”set key 0 0 1”,与之对应的状态是 conn_parse_cmd;”c”
与之对应的状态是conn_nread。
先看第一个状态:
-
conn_parse_cmd调用到try_read_command()
case conn_parse_cmd : if (try_read_command(c) == 0) { /* wee need more data! */ conn_set_state(c, conn_waiting); } break;conn_parse_cmd调用到try_read_command() - 对于我们例子输入是一种 ascii_protocol 格式(另外一种是binary protocol),它会最终调用到 process_command(中间省略了许多细节分析,但那不是本文的重点,感兴趣的话可以参考memcached.c中相关函数)
- process_command 再根据命令的类型(set , cas, gets等)转发给不同的函数处理,本文set的例子是转发给process_update_command
process_update_command不是本文的重点,我们只贴出部分代码(其他部分的代码也比较容易阅读)
static void process_update_command(conn *c, token_t *tokens, const size_t ntokens, int comm, bool handle_cas) {
....
it = item_alloc(key, nkey, flags, realtime(exptime), vlen);
...
ITEM_set_cas(it, req_cas_id);
c->item = it;
c->ritem = ITEM_data(it);
c->rlbytes = it->nbytes;
c->cmd = comm;
conn_set_state(c, conn_nread);
}
可以看出item_alloc后它并没有把alloc出来的item挂到LRU队列和hash链上,而是用c->item把它临时保存了起来。
这很合理,因为真正的数据这时候并没有达到。这时接收到的仅仅是命令(set
key 0 0 1).
接着是第二个读数据的状态:
它的流程是这样的
complete_nread –> complete_nread_ascii –> store_item
稍微注意一下,外部调用的大多是store_item, alloc_item …
这些函数定义在thread.c中,从它的名字可以看出,它们就是对do_xxx做一层浅浅的包装。这层浅浅的包装大多是计算当前item的hash值,并加锁。
enum store_item_type store_item(item *item, int comm, conn* c) {
enum store_item_type ret;
uint32_t hv;
hv = hash(ITEM_key(item), item->nkey, 0);
item_lock(hv);
ret = do_store_item(item, comm, c, hv);
item_unlock(hv);
return ret;
}
do_store_item的代码却定义在memcached.c 中,稍微看一下它的代码,就可以看出它的逻辑跟do_item_alloc, do_item_get都不相同,它是对不同的命令(set, cas, append…)执行不同的操作。这部分命令不属于item的范畴。见代码:
照例,我们可以猜测它的行为:
1) 用do_item_get从内存中取出对应的item作为old_item(当然可能不存在)
2) 拿到conn->item作为new_item
3) 根据不同的item调用不同的操作(replace等)
// 参数中的这个item从哪来的呢?正是前面process_update_command挂到conn结构体上的那个item
enum store_item_type do_store_item(item *it, int comm, conn *c, const uint32_t hv) {
char *key = ITEM_key(it);
// 这个是存在内存池中的数据
item *old_it = do_item_get(key, it->nkey, hv);
// 根据不同的命令执行对应的操作
// cas在这里起作用了。具体后面分析
// 如果是文中例子的set 操作,则会直接跑到这里,由于old_it不为空,会执行到item_replace
if (old_it != NULL)
item_replace(old_it, it, hv);
else
do_item_link(it, hv);
...
}
跟store_item和do_store_item一样,前者只是后者的一个包装。在这里item_replace将直接调用do_item_replace。
int do_item_replace(item *it, item *new_it, const uint32_t hv) {
...
do_item_unlink(it, hv);
// 在这里数据才真正被存储
return do_item_link(new_it, hv);
}
跟我们想象的一样,它调用do_item_unlink去掉旧的,然后调用do_item_link连接新的。
答案
是时候回答前面提出的问题了:
1 多线程支持:
-
锁机制:
通常来说,对于加锁有两种很暴力的思路:一种是所有的hash表加一个锁:这样做的最大的隐患是所有的item操作都排队阻塞在等待这把锁上。
另一种是每个item一把锁:这样系统将要花费很多额外的内存空间去维护这些(很大数量的)item锁。
memcached选择了一个折中的方案。对于内存池来说,memcached维护三种锁:
a) 引用计数锁:
pthread_mutex_t atomics_mutex = PTHREAD_MUTEX_INITIALIZER;
b) 细粒度的多个hash桶共用一个的锁
c) 粗粒度的所有hash表共用的全局锁
enum item_lock_types {
ITEM_LOCK_GRANULAR = 0,
ITEM_LOCK_GLOBAL
};
引用计数的情况就不必多说。我们来看下另外两把锁:
void item_lock(uint32_t hv) {
uint8_t *lock_type = pthread_getspecific(item_lock_type_key);
if (likely(*lock_type == ITEM_LOCK_GRANULAR)) {
mutex_lock(&item_locks[(hv & hashmask(hashpower)) % item_lock_count]);
} else {
mutex_lock(&item_global_lock);
}
}
所以在调用item_lock的时候,我们会根据锁的类型加不同的锁。
通常情况下,加的是第一种ITEM_LOCK_GRANULAR。
那么,什么时候需要一把全局锁?当hash容量不够,进行hash表扩张的时候。
当hash表扩张的时候,它会通过调用switch_item_lock_type
(在thread.c中)的函数来通知所有的工作线程换锁。
并锁住init_lock这个变量,直到所有的工作线程都更换成ITEM_LOCK_GLOBAL。
- 引用计数:
a) 每个linked的item,它的引用计数为1
b)每个线程在访问或使用某个item时都应该增加其引用计数,而在退出时释放期引用计数。
那么,考虑一种异常的情况,如果某个线程调用refcount_incr,还没来的及调用refcount_decr(item_remove)就因为某种原因而终止了。岂不是永远得不到释放?不会的,还是有机会减少引用计数的:
在do_item_alloc我们省掉的部分代码中有:
// 如果不为2 表明有其他的线程正在使用它,那么对其引用计数-1
// 随便对其进行LRU,判断最后访问时间是否小于
if (refcount_incr(&search->refcount) != 2) {
refcount_decr(&search->refcount);
if (search->time + TAIL_REPAIR_TIME < current_time) {
itemstats[id].tailrepairs++;
search->refcount = 1;
do_item_unlink_nolock(search, hv);
}
...
}
注意到代码中的TAIL_REPAIR_TIME,它定义在memcached.h中:
#define TAIL_REPAIR_TIME (3 * 3600)
它的含义是在可用内存低情况下,一个item对象能被lock(这里是refcount lock
即占用)的最长时间。
所以这个条件的意思是,如果ref->count == 1
有一个线程长时间占用它(超过TAIL_REPAIR_TIME ),
那么我们就干掉它(置引用计数为1,并不加锁的unlink它)。
2 LRU (Least Recently Used)
item数据结构中记录了两个时间:time和exptime。
item指其访问时间,也就是最后一次的更新时间。
exptime指其过期时间。
这两个时间都是相对于1970年1月1日的时间,所以可以认为它们是绝对时间。
做LRU时,只需要比较exptime和current_time,如果exptime < current_time就可以认为它过期了。
那么,我们还需要记录time这个变量干什么呢?item结构体的每一个变量都是有意义的。
考虑这样一种需求,我需要将缓存中早于某个时间的所有item全部flush掉。这个时候就要用到time了。(flush和expire的区别也就在此)。
命令flush_all就是处理这个要求的。
flush_all通常还可以带一个时间参数,表示从现在开始多少秒。这个时间参数会被换算成绝对时间保存在settings.oldest_live中。(默认的oldest_live为0,表示未设置)
rel_time_t oldest_live; /* ignore existing items older than this */
接下来的问题是,这个“早于某个时间”是如何起作用的呢?
一种可能的解决方案是:我们可以开一个线程,对所有的item进行一次遍历,来逐个比较它们的time和flush 设的time。
初看起来这样的解决思路是可行的,但如果我设的时间是现在开始的未来时间呢?难道还要设一个闹钟?
memcached给出了答案:延迟销毁。
当客户端输入flush_all 命令时会修改oldest_live的值,并把访问时间大于oldest_live的直接flush掉:
void do_item_flush_expired(void) {
int i;
item *iter, *next;
if (settings.oldest_live == 0)
return;
for (i = 0; i < LARGEST_ID; i++) {
for (iter = heads[i]; iter != NULL; iter = next) {
if (iter->time >= settings.oldest_live) {
next = iter->next;
if ((iter->it_flags & ITEM_SLABBED) == 0) {
do_item_unlink_nolock(iter, hash(ITEM_key(iter), iter->nkey, 0));
}
} else {
/* We've hit the first old item. Continue to the next queue. */
break;
}
}
}
}
在这里贴上了完整的代码,由于LRU是时间降序排列,所以只需要从头开始遍历,遇到time < oldest_live就可以结束(因为它之后的节点time都会小于oldest_live)。
看到这里可能会有人觉得迷惑:flush_all 从字面上解释,它不是flush掉所有的吗?那么time < oldest_live的item怎么没有flush呢?
放心,逃不过的。前面提到的“延迟销毁”就起作用了,在do_item_alloc和do_item_get中它们都做了LRU操作。
聪明的你肯定已经想到了答案:
exptime < current_time or time < settings.oldest_live\
可以验证这一点。
这是在do_item_alloc中:
if ((search->exptime != 0 && search->exptime < current_time)
|| (search->time <= oldest_live && oldest_live <= current_time))
这是在do_item_get中:
if (settings.oldest_live != 0 && settings.oldest_live <= current_time &&
it->time <= settings.oldest_live) {
...
if (was_found) {
fprintf(stderr, " -nuked by flush");
}
}
else if (it->exptime != 0 && it->exptime <= current_time) {
...
if (was_found) {
fprintf(stderr, " -nuked by expire");
}
也可以动手操作验证这一点:
> set key 0 0 1
> c
STORED
> get key
VALUE key 0 1
c
END
// flush_all 之后
> flush_all
OK
> get key
END
如果打开了-vvv选项,在服务端我们可以看到debug 信息:
<30 get key
> FOUND KEY key \-nuked by flush
>30 END
3 CAS
cas全称叫做check and set。它的用法如下:
> gets key // 注意是gets 不是get
VALUE key 0 1 4 // 响应。可以看到cas的值为4
c
随后我们输入
> cas key 0 0 1 4
> a
STORED
这时候再gets key 得到 VALUE key 0 1 5 ; 可以看到casid 已经变成了5。
如果我们不输入正确的5:
> cas key 0 0 1 6
> c
系统会响应:
EXISTS\
不让我们存储。这部分代码在do_store_item中:
enum store_item_type do_store_item(item \*it, int comm, conn \*c, const uint32_t hv) {
...
else if (ITEM_get_cas(it) == ITEM_get_cas(old_it)) { // 相等则存储
...
item_replace(old_it, it, hv);
stored = STORED;
} else { // 不相等则不存储,并置标志位为EXISTS
...
stored = EXISTS;
}
...
}
对于cas不相等的情况并没有执行item_replace,而是直接退出了。
那么casid 到底是个什么东西呢?在item数据结构中已经看到它是一个uint64_t
也就是一个64bit的数据。items.c中定义一个函数来获取casid:
uint64_t get_cas_id(void) {
static uint64_t cas_id = 0;
return ++cas_id;
}
4 hash 查找:
还记得在前面do_item_get函数解析代码吗?
assoc_find这部分代码没有解释。
它是这样做的:
item *assoc_find(const char *key, const size_t nkey, const uint32_t hv) {
item *it;
unsigned int oldbucket;
// 找到所在的桶
if (expanding &&
(oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket)
{
it = old_hashtable[oldbucket];
} else {
it = primary_hashtable[hv & hashmask(hashpower)];
}
// 再逐一比较链表上所有item的key 和 nkey
item *ret = NULL;
int depth = 0;
while (it) {
if ((nkey == it->nkey) && (memcmp(key, ITEM_key(it), nkey) == 0)) {
ret = it;
break;
}
it = it->h_next;
++depth;
}
MEMCACHED_ASSOC_FIND(key, nkey, depth);
return ret;
}
好了,到现在,大部分的hash内存管理的代码都已经解释清楚。当然还有一些其他的细节automove等。感兴趣的朋友可以自己参考相关代码。
总结
memcached的“内核”还是跟SGI次级空间配置很相似的,也可以说memcached内存管理就是它的升级版,它升级的地方在:
- LRU 置换算法
- CAS 安全写机制
- refcount 线程安全机制
- lock 来保证操作原子性
- hash 表来实现快速的查找和访问
当然这些好处的代价就是:
sizeof(item)
额外的内存空间以及可能的内部碎片(比如在128的chunk中存储100bytes,额外的28bytes就被浪费掉了。而SGI内存池会选择104bytes的chunk)
睿初科技软件开发技术博客,转载请注明出处
blog comments powered by Disqus
发布日期
标签
最近发表
- volatile与多线程
- TDD practice in UI: Develop and test GUI independently by mockito
- jemalloc源码解析-核心架构
- jemalloc源码解析-内存管理
- boost::bind源码分析
- 小试QtTest
- 一个gtk下的目录权限问题
- Django学习 - Model
- Code snippets from C & C++ Code Capsule
- Using Eclipse Spy in GUI products based on RCP
文章分类
- cpp 3
- wxwidgets 4
- swt/jface 1
- chrome 3
- memory_management 5
- eclipse 1
- 工具 4
- 项目管理 1
- cpplint 1
- 算法 1
- 编程语言 1
- python 5
- compile 1
- c++ 7
- 工具 c++ 1
- 源码分析 c++ 3
- c++ boost 2
- data structure 1
- wxwidgets c++ 1
- template 1
- boost 1
- wxsocket 1
- wxwidget 2
- java 2
- 源码分析 1
- 网路工具 1
- eclipse插件 1
- django 1
- gtk 1
- 测试 1
- 测试 tdd 1
- multithreading 1